Data Science-Pakete
Wählen Sie eines unserer Servicepakete auf Grundlage Ihrer Bedürfnisse und Anforderungen.
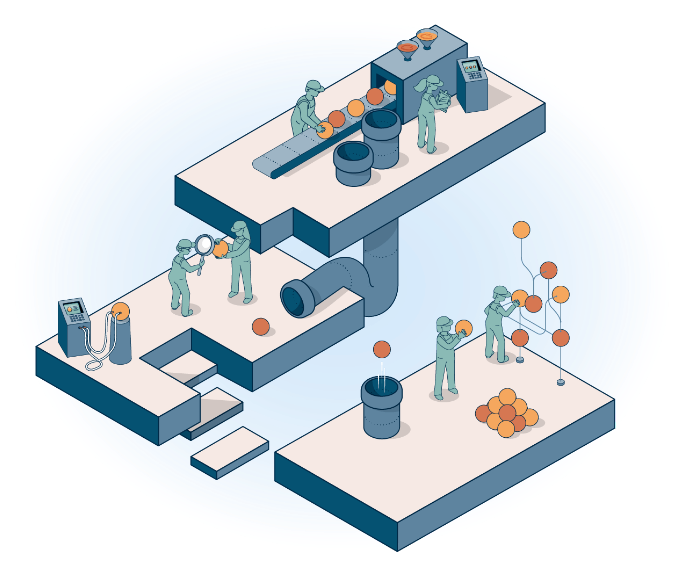
Wählen Sie eines unserer Servicepakete auf Grundlage Ihrer Bedürfnisse und Anforderungen.


Über 10 Jahre in der Data Science Branche haben uns eine Menge Erfahrung eingebracht. Die folgenden Services stehen Ihnen zur Verfügung.

Werfen Sie einen Blick auf unsere neuesten Podcast-Episoden, Blogbeiträge und Open Source-Projekte.











