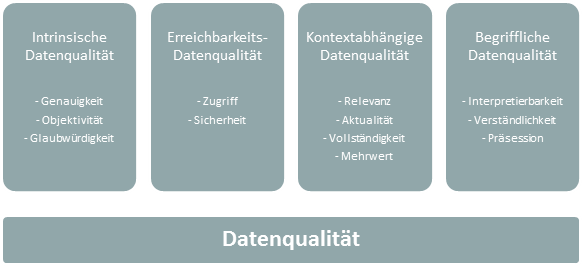
Klassifikation der Datenqualität
Die meisten Ansätze greifen für die Analyse der Datenqualität auf verschiedene Kriterien zurück. Die Kriterien sollen sowohl die Analyse von Datenproblemen als auch ihre Korrektur erleichtern. Um zwischen „qualitativ guten“ und „qualitativ schlechten“ Daten unterscheiden zu können, werden wir in der vorliegenden Artikelserie zwischen den Kriterien intrinsische, Erreichbarkeits-, kontextabhängige und begriffliche Datenqualität unterscheiden.
Die Kriterien für die Eingruppierung von Datenqualität werden im Folgenden kurz zusammengefasst. Der Kriterienkatalog macht deutlich, dass Datenqualität nicht ausschließlich auf die technischen Perspektive reduziert werden sollte, sondern auch wesentlich über den Inhalt der Daten bestimmt wird. Bekommt beispielsweise ein Nutzer irrelevante Daten, ist dies ebenfalls ein Zeichen für schlechte Datenqualität.
- Intrinsische Datenqualität: Hier geht es um die Qualität der Daten an sich. Gemeint ist damit die Genauigkeit und Objektivität mit der Daten bestimmt werden, und die Glaubwürdigkeit der Daten: Wurden Daten gerundet?
- Erreichbarkeits-Datenqualität: Hier geht es um die Erreichbarkeit und Sicherheit der Daten: Wird die Verfügbarkeit der Daten durch eine Verarbeitung verzögert?
- Kontextabhängige Datenqualität: Zentrum dieses Kriteriums ist die situative Relevanz, Aktualität, Vollständigkeit und Verwertbarkeit der Daten: Sind die Daten vollständig oder sind fehlerbedingte Datenlücken entstanden?
- Begriffliche Datenqualität: Hier geht es um die Interpretierbarkeit, Verständlichkeit und Präzession der Daten aus Sicht des Nutzers: Sind die Daten für den Nutzer verständlich bzw. kann er sie einfach interpretieren?