Die mächtige Open Source-Lösung - R
R entstand 1997 als Open Source-Alternative zur damals verbreiteten kommerziellen Statistik-Software S-PLUS, deren Programmiersprache "S" von R nachgebildet wird. R versteht sich im Sprachgebrauch des sog. Core-Teams als "Statistik-Umgebung" (als Gegenpol zu einer "Statistik-Software"). Dies soll das offene Paket-Konzept von R betonen. R besteht aus einigen Core-Paketen, die die Basisfunktionalität bereit stellen, und lässt sich beliebig durch Pakete erweitern. Während das Gros dieser Pakete ebenfalls unter einer Open Source-Lizenz verfügbar ist, erlaubt die R-Lizenz auch das Anbieten von Erweiterungs-Paketen unter kommerzieller Lizenz. Zum Teil wird die Weiterentwicklung von R auch durch solche Pakete querfinanziert, die z.B. als Auftragsarbeit für die Pharma-Branche entwickelt werden.
In den ersten Jahren führte R noch ein Nischendasein und wurde insbesondere von Statistikern und Biometrikern an Universitäten eingesetzt. Die Akzeptanz und die Anstrengungen für die Weiterentwicklung von R sind seitdem kontinuierlich gewachsen. Das Image einer minimalistischen Statistik-Umgebung, die sich nur von Nerds bedienen lässt, hat R schon lange abgelegt. Der Funktionsumfang von R übertrifft die kommerzielle Konkurrenz in vielen Bereichen deutlich. Im Kern ist R vor allem eine extrem leistungsfähige und sauber strukturierte Programmiersprache. Erweiterungspakete fügen dieser Sprache neue Funktionen hinzu.
Im folgenden wird R hinsichtlich des im ersten Teil der Artikelserie vorgestellten Kriterienkatalogs genauer untersucht:
Methoden: Statistik vs. Machine Learning
Allein im offiziellen Package-Repository CRAN ("Comprehensive R Archive Network") finden sich derzeit über 12 000 Pakete. Hinzu kommen noch Pakete aus weiteren Repositorys wie Bioconductor oder Pakete, die von Unternehmen, Forschungseinrichtungen oder Universitäten angeboten werden. Da R sich insbesondere in der wissenschaftlichen Community durchsetzen konnte, werden neue statistische Methoden auf Fachkonferenzen und in Veröffentlichungen regelmäßig zusammen mit einer Referenzimplementation in R vorgestellt. Keine andere Statistik-Software hat eine so große Community wie R. Python als generelle Programmiersprache übertrifft R hier zwar, doch hinsichtlich des Statistik-Aspekts nimmt R, dicht gefolgt von Python, den ersten Platz ein. Neben den kontinuierlichen Anstrengungen des Core-Teams ist es vor allem dieser breiten Community zu verdanken, dass R von allen betrachteten Statistik-Programmen mittlerweile die breiteste Methoden-Unterstützung mitbringt. Über CRAN bietet R zudem eine umfassende Auswahl an Machine Learning-Funktionalität. Einige Pakete wie caret, e1071 oder nnet geben AnwenderInnen Zugriff zu den meist genutzten state-of-the-art Methoden. Das Rennen um die beliebteste Machine Learning-Software ist eng zwischen R und Python, wobei die Entscheidung meist auf ein Unentschieden hinausläuft und letztlich subjektive Kriterien den Ausschlag geben. Schaut man weiter in Richtung Deep Learning / AI sind zwar R-Pakete für die gängigsten AI-Frameworks verfügbar, doch hier erfreut sich Python weit größerer Beliebtheit. Das mag an dessen besserer Integration liegen. Für einen detaillierteren Vergleich von R und Python lohnt sich ein Blick auf unseren Blog-Artikel "Python für R-Programmierer".
Bedienkonzept
Das Bedienkonzept ist gleichermaßen Stärke und Schwäche von R: Die eigentliche R-Installation zeigt nach dem Start nur eine einfache Kommandozeile. Unter MacOS und Linux verfügt die Anwendung noch über einige Features wie Syntax-Highlighting. Unter Windows ist R dagegen minimalistisch. Zwar gibt es mit dem "R Commander" eine rudimentäre Menü-Oberfläche, die R jedoch in seiner Flexibilität beschneidet und nur einen Bruchteil der R-Funktionen abdeckt. Die wahre Stärke von R liegt in der konsequenten Verwendung der leistungsfähigen Programmiersprache, die auch fortgeschrittene Konzepte wie Objektorientierung unterstützt und es erlaubt, den vollen Funktionsumfang von R zu erschließen. In R lässt sich alles automatisieren und bis ins letzte Detail anpassen. Der Aufwand, eine optisch ansprechende Grafik zu erstellen, ist z.B. höher als in Excel, dafür lässt sich alles bis ins letzte Detail einstellen. Somit ist es möglich - voll automatisiert - Grafiken zu erstellen, die exakt dem Corporate Design einer Organisation entsprechen. Mit RStudio existiert eine komfortabe quelloffene Entwicklungsumgebung, die auf allen gängigen Betriebssystemen lauffähig ist und Features wie Syntax-Highlighting, Code-Folding, Auto-Completion, Git-Integration und Debugging nachrüstet.
Nutzungsintensität und -frequenz
Die Einarbeitung in R beinhaltet primär das Erlernen der zugrundeliegenden Programmiersprache. Im Rahmen eines Crashkurses gelingt dies - der Erfahrung nach - innerhalb von zwei Tagen (auch für Personen, die bisher wenig Berührungspunkte mit anderen Programmiersprachen hatten). Beherrscht man den Umgang mit den wichtigsten Funktionen und ist mit einigen Besonderheiten von R vertraut, unterstützen einen die zahlreichen Hilfeseiten und die frei verfügbare Dokumentation bei der tieferen Einarbeitung in neue Methoden. Wie bei vielen Programmiersprachen geraten weniger genutzte Funktionen schnell in Vergessenheit, wenn nicht regelmäßig mit R gearbeitet wird. Daher eignet sich R eher für Personen, die regelmäßig statistische Auswertungen durchführen. Je tiefer man sich in R einarbeitet, desto mehr erschließt sich der Leistungsumfang, den R bietet.
Automatisierbarkeit
Neben Python als vollständige Programmiersprache und somit mit umfassender Automatisierbarkeit, wird R diesbezüglich von keiner anderen Statistik-Software übertroffen. Die R-Skripte lassen sich Out-of-the-Box über die Kommandozeile ausführen. Einmal vorbereitete Analysen lassen sich so zeitgesteuert (unter Windows mit dem Taskplaner unter Linux per Cron-Job) ausführen. Ebenso problemlos lassen sich R-Skripte aus anderen Anwendungen heraus starten. Parameter können beim Aufruf z.B. als Umgebungsvariablen übergeben werden. Mit Shiny existiert ein Server, der R-Skripte um ein Webinterface erweitert und es ermöglicht, R-Skripte interaktiv und komfortabel über den Browser auszuführen.
Umfang der zu analysierenden Daten
Grundsätzlich ist R so konzipiert, dass zu analysierende Daten komplett in den Arbeitsspeicher geladen werden müssen. Für die Analyse größerer Datensätze setzt R leistungsfähige Hardware, insbesondere einen großen Arbeitsspeicher, voraus. Für solche Anwendungen sollte R unbedingt auf einem 64 Bit-Betriebssystem ausgeführt werden, um den Arbeitsspeicher nicht noch künstlich zu limitieren. Die Verwendung von Datenbanken, der Rückgriff auf Hadoop oder die Verwendung von Erweiterungs-Paketen wie "ff" ermöglichen es, diese Limitationen in einigen Fällen zu umgehen. Sollen große Datensätze nur gelegentlich mit R analysiert werden, ist die Nutzung der Amazon Web Services (AWS) eine Alternative zur Anschaffung eigener Hardware. AWS unterstützt die Verwendung von R z.B. im Rahmen der EC2-Services. Darüber hinaus finden sich auch Anleitungen zur Einbindung von R in Elastic MapReduce. Eine einfache In-House-Lösung besteht darin, einen leistungsfähigen Server mit großem Arbeitsspeicher für die Installation der Server-Version von RStudio zu nutzen und berechtigten Personen im Unternehmen den Zugriff auf diese Umgebung via Browser freizugeben.
Sicherung der Datenqualität
In diesem Bereich profitiert R von der Breite an unterstützten Methoden. Alle gängigen Ausreißertests sind in R verfügbar. Ebenso ist R führend, was die Unterstützung robuster Methoden angeht. Per "Default" sind viele Funktionen in R so eingestellt, dass sie z.B. zunächst einen fehlenden Wert zurück geben, wenn die Daten selbst fehlende Werte enthalten (dies gilt z.B. für die Berechnung des Mittelwerts). Dieses Verhalten trägt dazu bei, dass fehlende Werte nicht einfach übersehen werden. Erst durch Setzen des Parameters na.rm = TRUE ignoriert R fehlende Werte. Andere Funktionen, z.B. lm(...) zur Schätzung (multipler) linearer Regressionsmodelle, geben standardmäßig eine Reihe diagnostischer Grafiken (u.a. mit Hebelwerten) aus, die es dem Anwender leicht machen, Ausreißer oder Extremwerte in den Daten zu identifizieren.
Installationsszenario
Hinsichtlich der Verfügbarkeit für unterschiedliche Plattformen setzt R Maßstäbe. Installer bzw. Pakete gibt es für Windows, Mac OS X und Linux (32 und 64 Bit). Darüber hinaus gibt es die Möglichkeit, den Sourcecode herunterzuladen und für weitere Plattformen (z.B. diverse Unix-Derivate) zu kompilieren. Die Server-Version von RStudio bietet die Möglichkeit, R von einem beliebigen Browser aus unter Wahrung der vollen Funktionalität zu bedienen.
Performance
Hinsichtlich der Performance ist eine generelle Aussage schwierig. Grundsätzlich gilt R als vergleichsweise schnell, wobei dieser Vorteil z.T. daher rührt, dass R alle Daten im Arbeitsspeicher hält, während andere Statistik-Programme z.T. größere Datensätze auch standardmäßig von einem Block-Device öffnen können. Darüber hinaus bietet R durch Einsatz des Pakets "compiler" die Möglichkeit, R-Code vorab in Bytecode zu übersetzen und dadurch insbesondere die Ausführung von häufig aufgerufenen Funktionen oder die Ausführung von Schleifen deutlich zu beschleunigen. Darüber hinaus lassen sich Funktionen in C, C++ oder Python programmieren und nahtlos in R einbinden. Viele Pakete nutzen diese Option für zeitkritische Methoden. Standardmäßig nutzt R auf einem PC mit mehreren Prozessoren oder Kernen nur einen Kern simultan. Lediglich einige Funktionen, die an Bibliotheken wie ATLAS oder BLAS weitergereicht werden, lassen sich parallelisiert ausführen. Zu beachten ist, dass die mit R gelieferte Bibliothek einen Kompromiss darstellt und sich durch die Verwendung fremder Bibliotheken, z.B. GotoBLAS, erhebliche Geschwindigkeitsgewinne erzielen lassen. Zudem existiert mit dem "parallel"-Paket eine Möglichkeit, einige Berechnungen durch expliziten Einsatz spezieller Funktionen zu parallelisieren. Unter Linux (und anderen Betriebssystem, die POSIX Threads unterstützen) gelingt dies besonders effizient.
Rechteverwaltung
R kann auch unter eingeschränkten Rechten ausgeführt werden. Es besteht die Möglichkeit, z.B. ein zentrales (lokales) Paket-Repository über ein Netzlaufwerk für alle Nutzer einer Organisation einzubinden. Darüber hinaus verwendet R globale und nutzerspezifische Konfigurationsdateien, über die aber nur grundlegende Einstellungen gesteuert werden können. Da R keinen Zugriff auf ein zentrales Repository für Datensätze vorsieht, bringt es auch kein entsprechendes Berechtigungssystem mit. Es besteht aber natürlich die Möglichkeit, Daten über einen SQL-Server bereitzustellen (R hat eine hervorragende Unterstützung für alle gängigen Datenbank-Lösungen) und Zugriff auf Datenbanken, Tabellen sowie einzelne Spalten einer Tabelle über SQL zu regeln. Darüber hinaus bringt die für Linux verfügbare Server-Version von RStudio eine Authentifizierung über alle von PAM (Pluggable Authentication Module) unterstützen Module mit. Hierbei kann aber nur der Zugang zu R(Studio) limitiert werden, während sich unter den Usern, die Zugriff erhalten, die Rechte nicht weiter differenzieren lassen.
Lizenzmodell
R selbst steht als Open Source Statistik-Umgebung unter der GPL-2 bzw -3 Lizenz und kann kostenlos privat und kommerziell eingesetzt werden. Einige Pakete oder Dateien stehen unter anderen Lizenzen. Bei der Nutzung - aber auch Erweiterung - von R besteht damit große Flexibilität.
Integration mit anderen Anwendungen
Kein anderes Statistik-Programm ist in dieser Hinsicht auch nur annähernd mit R vergleichbar. R kann über native Treiber u.a. mit folgenden Datenbanken kommunizieren: MySQL, PostgreSQL, Oracle (s. a. Oracle R Enterprise) und Teradata. Darüber hinaus kann R über ODBC und JDBC mit nahezu beliebigen Datenbanken (u.a. auch Microsoft SQL Server) kommunizieren. Zunehmend bieten auch andere Statistik-Programme (z.B. SAS und SPSS) eine Integration von R-Skripten, um von dem Funktionsumfang von R zu profitieren. Darüber hinaus gibt es Interfaces, um R mit anderen Programmiersprachen zu verknüpfen, so kann R z.B. Objekte mit JAVA austauschen (s. JRI bzw. rJava). Auch im Business Intelligence-Sektor wächst die Unterstützung von R. So integriert Microstrategy R seit der Version 9.2.1 über das R Integration Pack. Google stellt z.B. für seine Chart Tools und Analytics eine Schnittstelle zu R bereit. Für Big Data-Anwendungen gibt es verschiedene Lösungen, R in Hadoop (auf eigener Hardware oder auch über Amazon Web Services) einzubinden. Zu erwähnen ist noch Sweave, welches R mit dem leistungsfähigen und flexiblen Satzsystem LaTeX verknüpft und die automatische Erstellung komplexer Reports z.B. als PDF oder HTML ermöglicht. Die Liste ließe sich fast beliebig erweitern. Für alle Anwendungsszenarien, in denen es noch keine explizite Lösung gibt, bleibt immer noch die Variante, R-Skripte über die Kommandozeile auszuführen und Input/Output über Datenbanken, CSV-Dateien, etc. auszutauschen.
Branchenspezifische Anforderungen
R bietet eine spezifische Zertifizierung für den Einsatz in klinischen Versuchen (die sich aber nur auf ausgewählte Pakete bezieht) und lässt sich durch die Breite des unterstützten Methodenspektrums in nahezu jeder Branche einsetzen. Sehr stark verbreitet ist R an Universitäten und im Forschungsbereich. Auch im Pharma-Bereich wird R intensiv eingesetzt. Hier existieren neben zahlreichen offenen Paketen auch viele in Auftragsarbeit entstandene Pakete, die speziell auf die Anforderungen bestimmter Unternehmen zugeschnitten sind und nur intern eingesetzt werden. Die zunehmende Verbreitung von R zeigt sich mittlerweile auch durch eine immer größer werdende Verwendung der Software in Bereichen wie Online-Marketing oder Customer-Relationship-Management.
Akzeptanz
Mit der zunehmenden Verbreitung von R ist auch die Akzeptanz in den letzten Jahren stark gestiegen. In der Forschung hat sich R längst etabliert. Mittlerweile setzen auch immer mehr Unternehmen R aufgrund der hohen Flexibilität ein oder haben zumindest schon von der Existenz von R gehört.
Support
Für R gibt es durch die breite Community-Unterstützung zahlreiche frei verfügbare Manuals, Tutorials sowie aktive Foren, Blogs und Mailinglisten. Empfehlenswert sind u.a. Quick-R und R-bloggers. Das R-Journal erscheint zwei mal im Jahr als PDF und informiert über Änderungen, neue Pakete und Best Practices. Über verschiedene offizielle Mailinglisten wird individuelle Hilfe gegeben. Sofern beim Posten die gängigen Hinweise berücksichtigt werden, erhält man auf diesem Weg oft schnell und vor allem kompetente Unterstützung - nicht selten sogar von Mitgliedern des Core-Teams von R. Da die meisten Entwickler und viele Community-Mitglieder sehr erfahrene Statistiker sind, beinhaltet die Unterstützung oft nicht nur die Nutzung von R, sondern auch Hinweise auf passende statistische Methoden. Insgesamt ist der über die Foren gebotene Support manchem Hersteller-Support hinsichtlich Reaktionszeit und Kompetenz überlegen. Eine Garantie, dass eine Frage beantwortet wird, gibt es aber nicht. Diese Lücke schließen verschiedene Anbieter, die Support für R gegen Bezahlung bieten.
Angebot an Schulungen
Schulungen für R werden einerseits von Universitäten angeboten, in Deutschland u.a. an der Freien Universität Berlin oder der LMU München. Plattformen wie Coursera oder Data Camp ergänzen dieses Angebot um Online-Kurse. Abgerundet wird das Schulungsangebot durch zahlreiche kommerzielle Anbieter, die standardisierte oder flexible R-Schulungen auf verschiedenen Niveaus anbieten. Zu den größeren Anbietern zählt z.B. RStudio.
Vorhandene Qualifikation der Mitarbeiter
Noch vor wenigen Jahren wurde R - jenseits einiger Nischen - kaum in der universitären Ausbildung eingesetzt. An vielen Fachbereichen dominierte der Einsatz von SPSS. Das hat sich mittlerweile geändert. In Deutschland setzen diverse Universitäten R z.T. schon in Bachelor-Veranstaltungen ein. Gerade Berufseinsteiger bringen daher mittlerweile vereinzelt Kenntnisse in R mit. Häufig handelt es sich dabei allerdings lediglich um Grundkenntnisse. Da gerade die ersten Schritte in R eine Hürde darstellen, können diese Vorkenntnisse den Schulungsaufwand allerdings beträchtlich senken.
Stabilität/Innovativität
Das Core-Team bringt i.d.R. zwei Releases pro Jahr heraus. Kleinere Fixes (Änderungen in der dritten Stelle der Versionsnummer) gibt es bei Bedarf. Durch das Paket-Konzept gelingt es R, Stabilität und Innovativität zu vereinen. Die erwähnte Zertifizierung für klinische Versuche beweist die Verlässlichkeit der Pakete der Core-Distribution. Ähnliche Standards gelten auch für einige viel genutzte und gut gepflegte Erweiterungs-Pakete. Die unzähligen Erweiterungs-Pakete gewährleisten gleichzeitig die schnelle Verfügbarkeit neuer Methoden. Das Problem besteht darin, dass selbst die Aufnahme ins offizielle Paketrepository CRAN keine Garantie für einen ähnlich hohen Qualitätsstandard bietet. Für Pakete, die aus anderen Quellen geladen werden, gilt dies erst recht. Dem Laien fällt es oft schwer, die Qualität solcher Erweiterungen zu beurteilen. Dieses Problem sollte angesichts des Funktionsumfangs der Core-Distribution und einiger viel genutzter Zusatzpakete aber nicht überbewertet werden. Grundsätzlich stellt R eine sehr solide Infrastruktur zur sauberen Programmierung von Erweiterungen zur Verfügung. Wer sich daran hält, implementiert u.a. Tests, die bei jedem neuen Build sicherstellen, dass alles so funktioniert, wie es soll, und Änderungen keine ungewollten Nebenwirkungen entfalten. Wie bei freier Software üblich, besteht jedoch kein Zwang, sich an diese Richtlinien zu halten, wobei die Kontrolle durch die Community und deren aktive Beteiligung an der Entwicklung zu einem insgesamt sehr hohen Standard geführt haben.
Als Fazit eignet sich R heute für alle Anwendungsszenarien, in denen regelmäßig mit Statistik-Software gearbeitet wird. Hauptargumente stellen - neben den entfallenden Lizenzkosten für die Software selbst - vor allem die Breite unterstützter Methoden und die enorme Flexibilität und gute Automatisierbarkeit dar. Der Mehraufwand für die Einarbeitung zahlt sich bei regelmäßigem Einsatz der Software i.d.R. schnell durch erhöhte Produktivität aus. Die aktive Community bietet Support und garantiert die langfristige Weiterentwicklung der Software. Lediglich, wenn sehr große Datensätze auf vergleichsweise schwacher Hardware analysiert werden sollen, wenn Statistik-Software nur sporadisch genutzt wird oder wenn ausschließlich sehr spezielle Methoden gefragt sind, sollte der Einsatz von R kritisch hinterfragt werden.
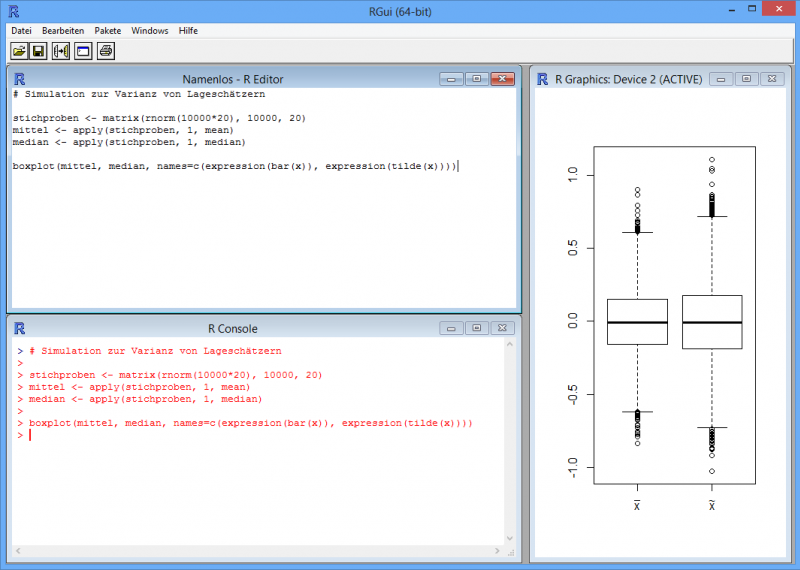 Umsetzung einer einfachen Simulation auf der R-Konsole (Skriptfenster - oben links, Konsole - unten links, Grafik-Fenster - rechts)
Umsetzung einer einfachen Simulation auf der R-Konsole (Skriptfenster - oben links, Konsole - unten links, Grafik-Fenster - rechts)
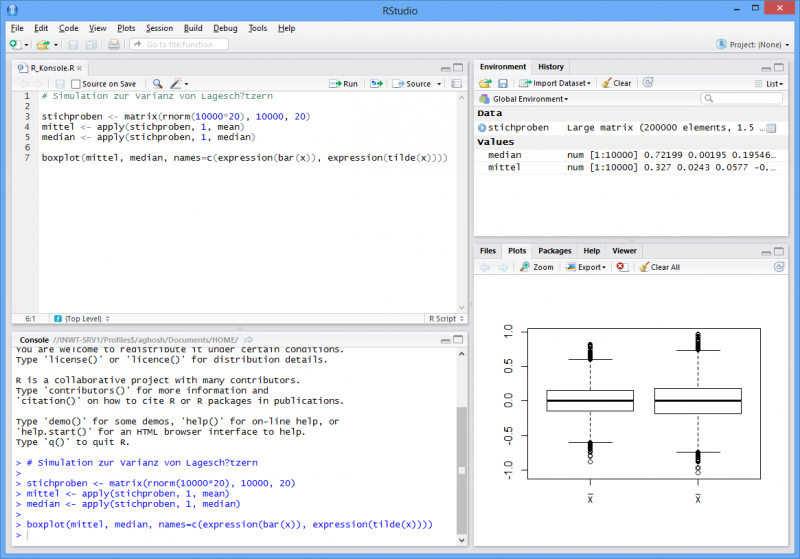 Umsetzung der selben Simulation mittels der deutlich komfortableren Oberfläche von RStudio.
Umsetzung der selben Simulation mittels der deutlich komfortableren Oberfläche von RStudio.
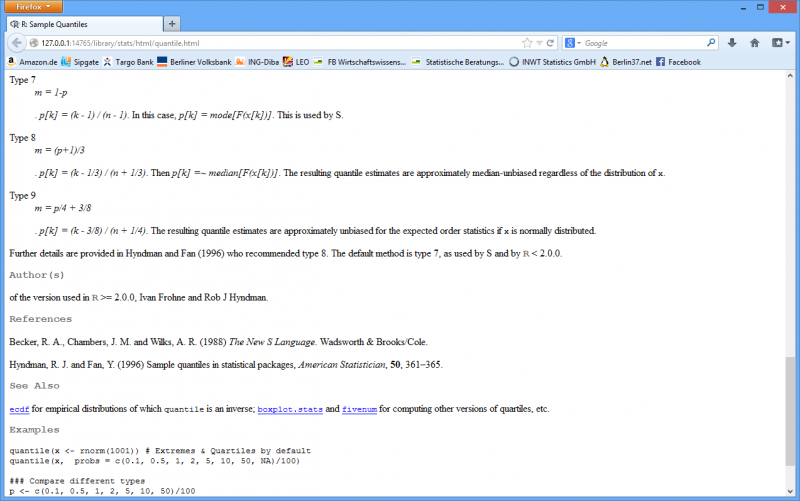 Zu jeder R-Funktion gibt es eine übersichtliche Hilfe-Seite, die neben grundlegenden Informationen häufig auch Literaturverweise enthält.
Zu jeder R-Funktion gibt es eine übersichtliche Hilfe-Seite, die neben grundlegenden Informationen häufig auch Literaturverweise enthält.
 Sweave verknüpft R mit LaTeX und ermöglicht die automatisierte Erstellung von Reports und Berichten.
Sweave verknüpft R mit LaTeX und ermöglicht die automatisierte Erstellung von Reports und Berichten.
 Quick-R: Die Seite bietet auf das wesentliche reduzierte Hilfestellungen zu vielen Aufgabenstellungen (u.a. Daten-Import und Grafiken).
Quick-R: Die Seite bietet auf das wesentliche reduzierte Hilfestellungen zu vielen Aufgabenstellungen (u.a. Daten-Import und Grafiken).





