Statistik zum Klicken - SPSS
SPSS ist eines der ältesten Statistik-Programme am Markt. Ursprünglich wurde SPSS von der eigenständigen Firma "SPSS Inc." Ende der 60er Jahre entwickelt. Der Name stand für "Statistical Package for the Social Sciences" und tatsächlich ist SPSS im Bereich der Sozialwissenschaft das dominierende Tool für statistische Analysen. Von den Universitäten wurde die Software in die Unternehmen getragen und entwickelte sich zum Quasi-Standard in vielen Bereichen. SPSS gab in manchen Fachgebieten den Fortschritt in Sachen statistischer Methoden vor: Viele Methoden wurden erst von einer breiteren Community aufgegriffen, nachdem sie in SPSS implementiert worden waren, und erfreuten sich dann sprunghafter Beliebtheit. Noch heute stoßen manche Autoren auf Probleme, wenn eingereichte Artikel Outputs anderer Statistik-Programme als SPSS enthalten, die von der SPSS-Konvention abweichen.
Erst allmählich bricht dieses Monopol auf und andere Statistik-Programme erhalten Einzug in die bis dato von SPSS dominierten Bereiche. SPSS, das zwischenzeitlich unter dem Namen „PASW Statistics“ (Predictive Analysis Software) firmierte, wurde mittlerweile vollständig von IBM übernommen und wird unter dem Namen „IBM SPSS Statistics“ angeboten und weiterentwickelt. Die Entwicklung des Produktportfolios fokussiert dabei stärker auf Anwendungen in der Marktforschung und dem Bereich „Predictive Analytics“. IBM implementiert Prozeduren, die nur eine minimale Konfiguration durch den Nutzer erfordern und zahlreiche Entscheidungen eigenständig treffen. Ein Beispiel dafür ist die Prozedur „Automatische lineare Modellierung...“, die eine Regression ausführt, dabei automatisch erklärende und abhängige Variablen festlegt, Variablen ggf. transformiert und bereinigt, die geeignete Kodierung der Variablen übernimmt und die Ergebnisse automatisiert aufbereitet. Diese Entwicklung ermöglicht es gerade weniger versierten Anwendern mit geringen Statistik-Kenntnissen, schnell präsentierbare Ergebnisse zu erzeugen. Erfahrene Anwender meiden solche Funktionen häufig, da deren Nutzung mit einem gewissen Kontrollverlust einhergeht.
Im Folgenden wird SPSS hinsichtlich des im ersten Teil der Artikelserie vorgestellten Kriterienkatalogs genauer untersucht:
Methoden: Statistik vs. Machine Learning
SPSS bietet eine gute Unterstützung für häufig gebrauchte Methoden. Dazu gehören deskriptive Statistiken, Grafiken, die multiple lineare Regression, parametrische und nicht-parametrische Tests, Faktorenanalyse, Hauptkomponentenanalyse, Clusteranalyse, Diskriminanzanalyse, Conjoint-Analyse sowie diverse komplexere Modelle (GLM, GLMM, …). Mit SPSS Amos existiert ein separates leistungsstarkes Tool für Strukturgleichungsmodelle. Hervorzuheben ist die von SPSS gebotene Möglichkeit, für einen geladenen Datensatz eine Fallgewichtung einzustellen, die dann transparent in allen Analysen Berücksichtigung findet. Im Vergleich zu STATA oder EViews deckt die Unterstützung für Panel-Modelle und Zeitreihen eher Grundlagen ab. Hinsichtlich der Breite und teilweise auch der „Tiefe“ unterstützter Methoden kann SPSS mit den Konkurrenten R und SAS in vielen Bereichen nicht mithalten. Ein anderes stetes Ärgernis ist die fehlende automatische Kodierung von Variablen mit nominalem oder ordinalem Messniveau in der einfachen Regressions-Prozedur (nominale Variablen mit mehr als zwei möglichen Ausprägungen müssen manuell z.B. in Dummies kodiert werden, während andere Prozeduren in SPSS, wie die logistische Regression, diese Kodierung automatisch durchführen), die z.B. bei R Standard ist. Zu beachten ist, dass SPSS aus zahlreichen Modulen besteht, die je nach Version (s. Lizenzmodell) nicht alle zur Verfügung stehen. Zusätzlich zu statistischen Methoden deckt IBM SPSS ein hinreichendes Spektrum an Machine Learning-Verfahren ab. Für typische Fragestellungen ist dieses Angebot mehr als ausreichend, allerdings kann SPSS in Bezug auf die Breite an Verfahren nicht mit Python oder R konkurrieren. IBM bietet darüber hinaus mit Watson ein auf AI spezialisiertes Produkt an. Dieses ist aber weniger auf ad-hoc Analysen zugeschnitten, sondern eignet sich eher zum Bau von AI-Agents (Bots) oder zur Integration in automatisierte Anwendungen.
Bedienkonzept
Anders als STATA oder R verfügt SPSS über eine Klick-Oberfläche, über die sich fast alle unterstützen Funktionen aufrufen lassen. Während SAS aus verschiedenen Modulen mit z.T. unterschiedlicher Bedienlogik besteht, bietet SPSS seinen Nutzern eine einheitliche Oberfläche. Nicht alle Methoden finden sich dort, wo man sie erwartet (so ist zum Beispiel die Funktion zum Testen auf Normalverteilung mittels Kolmogorov-Smirnov- oder Shapiro-Wilk-Test unter Analysieren > Deskriptive Statistiken > Explorative Datenanalyse... > Diagramme... versteckt). Hat ein Nutzer sich an diese wenigen Eigenheiten erst einmal gewöhnt, lässt sich SPSS so einfach bedienen wie wohl kein anderes Statistik-Programm. Selbst wenn umfangreichere Neuerungen anstehen, behält SPSS die alten Menüs für längere Zeit als Alternative zu den neuen Funktionen bei, so dass neue Versionen i.d.R. wenig oder keine Umgewöhnung erfordern. Die einfache Oberfläche ist wesentliches Alleinstellungsmerkmal von SPSS und hat der Software gleichzeitig einen zwielichtigen Ruf eingebracht. Insbesondere Statistiker kritisieren, dass es mit SPSS möglich ist – ohne zu wissen, was man tut – so lange herumzuklicken, bis irgendwann eine (sinnlose) Auswertung auf dem Bildschirm erscheint. Die automatisierten Prozeduren verkürzen den Weg dorthin noch weiter.
Nutzungsintensität und -frequenz
Durch das einfache Bedienkonzept bietet sich SPSS als einzige Software auch für Wenig- und Gelegenheits-Nutzer an. Während bei Umgebungen wie R oder STATA nach einer längeren Nutzungspause schnell die Namen einiger Funktionen in Vergessenheit geraten und erneute Einarbeitung nötig wird, findet man sich in den Menüs von SPSS jederzeit wieder schnell zurecht. Für Heavy-User bietet SPSS u.a. Makros, eine Skriptsprache sowie die Möglichkeit, über Erweiterungen Python, R, Java und .NET-Code einzubinden.
Automatisierbarkeit
Nahezu jedes Dialogfeld in SPSS kann entweder direkt ausgeführt werden (durch einen Klick auf „OK“) oder ein Skript generieren (durch einen Klick auf „Einfügen“). Über die hinter der Benutzeroberfläche stehende Skript-Sprache lassen sich Aufgaben und Abläufe weitestgehend automatisieren. Lediglich einige wenige Veränderungen, die z.B. nachträglich an der Formatierung des Outputs vorgenommen werden, lassen sich auf diese Weise nicht reproduzieren. Umgekehrt gehen die Möglichkeiten der Skript-Sprache an vielen Stellen über die der Dialogfelder hinaus. Die SPSS-Makro-Sprache ergänzt typische Programmierkonzepte zur Ablaufsteuerung (z.B. Schleifen), die es ermöglichen, kompakte Syntax auch für wiederkehrende Aufgaben zu generieren. Plug-ins ermöglichen es, Python, R, Java und .NET zu verwenden, um SPSS um eigene Funktionen zu erweitern. Im direkten Vergleich z.B. zu R, welches eine intuitive und vor allem einheitliche Syntax bietet, ist die SPSS-Lösung aus Syntax- und Makro-Sprache jedoch weniger leistungsfähig und gleichzeitig komplizierter. Typischerweise werden andere Lösungen eingesetzt, wenn die Automatisierbarkeit im Vordergrund steht, während SPSS seine Stärke in der interaktiven Analyse von Daten ausspielen kann.
Umfang der zu analysierenden Daten
Ursprünglich wurde SPSS als klassisches Desktop-Produkt entwickelt. Trotzdem kann SPSS auch mit größeren Datensätzen umgehen und ist nicht zwingend darauf angewiesen, die kompletten Daten im Arbeitsspeicher zu halten. Alternativ zur lokalen Berechnung auf dem Client bietet IBM die Auslagerung der Berechung auf die IBM Cloud an. Clients können sich im „Distributed Mode“ mit dem Server verbinden und dort Berechnungen durchführen. In diesem Modus kann der Server Daten direkt von einem zentralen Storage oder einer Datenbank einlesen – lediglich die Ergebnisse der Berechnung müssen über das Netzwerk zum Client übertragen werden. Datensätze mit über einer Mio. Fällen stellen auf aktueller Client-Hardware i.d.R. keine Probleme dar. Bei Einsatz der Server-Variante lassen sich – abhängig von der verwendeten Hardware – auch deutliche größere Datenmengen bewältigen.
Sicherung der Datenqualität
In SPSS können mit wenigen Klicks für alle im Datensatz enthaltenen Variablen übersichtliche Tabellen mit deskriptiven Kennzahlen und Grafiken erstellt werden, die es ermöglichen, eine grundlegende Einschätzung der Datenqualität vorzunehmen. Darüber hinaus kann SPSS über die Funktion „Explorative Datenanalyse…“ robuste Lage- und Streuungsparameter berechnen und enthält Unterstützung für nicht-parametrische Tests. Das Modul SPSS Data Preparation enthält zudem spezielle Methoden zur Vorbereitung und (automatisierten!) Bereinigung von Daten.
Installationsszenario
Die Desktop-Version von SPSS Statistics gibt es für Mac OS X, Linux (Debian, Red Hat) und Windows (XP, Vista, 7, 8, 10). Der SPSS Statistics Server ist unter AIX, Linux (Red Hat, Suse), Solaris und Windows lauffähig. IBM pflegt eine sehr detaillierte Aufstellung der Systemanforderungen für den Client und den Server.
Performance
SPSS läuft in einer eignen JAVA-Umgebung. Der Client startet selbst auf aktueller Hardware relativ langsam. Auf älterer Hardware kann bis zum Erscheinen der Oberfläche eine halbe Minute vergehen. Was die eigentlichen Berechnungen anbelangt, liegt SPSS im Mittelfeld. Im Whitepaper „Understanding the Benefits of IBM SPSS Statistics Server” nimmt IBM einen Benchmark vor, der die Performance der Desktop-Version mit der der Server-Version vergleicht.
Rechteverwaltung
Für die Desktop-Version sind keine speziellen Mechanismen zur Steuerung von Rechten vorgesehen. Die Server-Version ermöglicht Verschlüsselung der Kommunikation zwischen Client und Server, Passwort-Schutz für Daten und generierten Output sowie die Arbeit mit serverseitig gespeicherten Daten. Beim Zugriff auf Datenbanken lassen sich zudem die dort hinterlegten Berechtigungen zur Steuerung des Zugriffs einsetzen.
Lizenzmodell
Unterschieden wird einerseits zwischen „License + SW Subscription & Support 12 Months“ (unbegrenzt gültige Lizenz und Updates/Support 12 Monate ab dem Kauf) und „Initial Fixed Term License + SW Subscription & Support 12 Months“ (zeitlich beschränkt gültige Lizenz für 12 Monate inkl. Updates und Support innerhalb dieses Zeitraums) sowie „Authorized User“ (an eine Person gebundene Lizenz, die Installation auf mehreren Geräten erlaubt) bzw. „Concurrent User“ (erlaubt die Nutzung durch einen Nutzer zu einem Zeitpunkt) auf der anderen Seite.
SPSS besteht aus verschiedenen Modulen, die entweder separat oder alternativ in Form sog. „Editionen“ im Bündel erworben bzw. lizensiert werden können. Das Basismodul ist IBM Statistics Base enthält nur Unterstützung für grundlegende statistische Methoden und kostet ab ca. 1.200 € brutto (Listenpreis: Authorized User, Lizenz inkl. Updates und Support für 1 Jahr). Aufgrund der beschränkten Fähigkeiten ist – abgesehen von sehr speziellen Nutzungsszenarien – i.d.R. der Kauf bzw. die Lizensierung einer umfangreicheren Edition sinnvoller. Bereits die Standard-Edition ist für viele Nutzungsszenarien ausreichend und beinhaltet neben linearen Modellen auch die Logistische Regression und weitere nicht-lineare Modelle. Die Preise beginnen hier bei knapp 2.700 € brutto (Listenpreis: Authorized User, Lizenz inkl. Updates und Support für 1 Jahr). Die Professional-Edition bringt zusätzlich zu den in der Standard-Edition enthaltenen Modulen Unterstützung für automatische Datenbereinigung, Imputation von fehlenden Werten, Entscheidungsbäume und Forecasting (Zeitreihenmodelle). Die Preise für die Professional-Edition beginnen bei knapp 5.500 € brutto (Listenpreis: Authorized User, Lizenz inkl. Updates und Support für 1 Jahr). Die Premium-Edition erweitert die Professional-Edition um Strukturgleichungsmodelle, Funktionen zur Bestimmung einer geeigneten Stichprobengröße, Bootstrapping, Methoden speziell für das Direkt-Marketing (dieses Modul bündelt statistische Verfahren zur Beantwortung typischer Fragestellungen im Marketing, z.B. Kundensegmentierung). Die Preise für diese Editionen beginnen bei gut 8.000 € brutto (Listenpreis: Authorized User, Lizenz inkl. Updates und Support für 1 Jahr). Eine Übersicht vergleicht die Editionen hinsichtlich der gebotenen Funktionalität.
Viele Universitäten bieten für Studierende und Mitarbeiter eine für den Zeitraum 01.10. bis 30.09. des Folgejahres gültige SPSS-Lizenz für ca. 60 bis 70 €, deren Funktionsumfang sich an der Premium-Edition (ohne Strukturgleichungsmodelle) orientiert. Darüber hinaus kann eine 14 Tage lauffähige Test-Version (nach Registrierung) über die Webseite von IBM heruntergeladen werden.
Integration mit anderen Anwendungen
Plug-ins ermöglichen es, die Funktionalität von SPSS durch in Python, R, Java oder .NET geschriebenen Code zu erweitern. Speziell den Möglichkeiten durch die Integration von R widmet IBM ein eigenes Whitepaper „The power of IBM SPSS Statistics and R together“. Noch einen Schritt weiter geht das Modul SPSS Statistics Developer, welches es Spezialisten ermöglicht, R und Python zu nutzen, um eigene Funktionen zu implementieren, die anschließend innerhalb von SPSS über die gewohnte Klick-Umgebung genutzt werden können. Mit dem Modul können spezielle Funktionen von R innerhalb von SPSS über einen selbst entwickelten Dialog zugänglich gemacht werden.
Das Modul SPSS Advantage for Microsoft Excel integriert ausgewählte SPSS-Funktionen in Microsoft Excel. Den Fokus hat IBM dabei auf für das Marketing relevante Methoden (u.a. Kundensegmentierung), Methoden zur Überprüfung und Bereinigung von Daten sowie Methoden zur Datentransformation gelegt.
SPSS kann problemlos Daten u.a. aus folgenden Quellen übernehmen: DB2, Microsoft Active Directory, Microsoft SQL Server, MySQL, Netezza Data Warehouse, Oracle-Datenbanken, Salesforce (CRM) und Teradata.
Branchenspezifische Anforderungen
Historisch verwurzelt ist SPSS im Bereich der Sozialwissenschaften. Darüber hinaus hat die Software auch in Unternehmen weite Verbreitung gefunden. In der Medizin wird SPSS ebenfalls in kleineren Projekten (typischerweise im Rahmen von Doktorarbeiten) eingesetzt. Die Entwicklung fokussiert in letzter Zeit stark auf den Bereich Marketing. SPSS bietet hier speziell auf typische Anwendungsszenarien (z.B. Kundensegmentierung, Direktmarketing) abgestimmte und in der Bedienung stark vereinfachte Prozeduren an.
Akzeptanz
Insbesondere durch die einfache Bedienbarkeit genoss SPSS in vielen Bereichen lange Zeit fast eine Monopolstellung. In einigen Fachgebieten richtete sich gar die Wahrnehmung der Statistik nach dem in SPSS verfügbaren Methodenspektrum. Statistische Methoden fanden in einer breiten Community erst Beachtung, nachdem SPSS diese implementierte. In zahlreichen Journals haben sich die Outputs von SPSS zum Quasi-Standard für die Präsentation statistischer Ergebnisse entwickelt. Nutzer alternativer Statistik-Software werden gelegentlich von den Gutachtern nicht selten aufgefordert, ihre Outputs entsprechend umzuformatieren. Insbesondere die zunehmende Konkurrenz und Popularität von R hat SPSS in den letzten Jahren jedoch Marktanteile gekostet. Trotzdem gibt es derzeit speziell hinsichtlich der einfachen Bedienbarkeit keine echte Alternative zu SPSS für Anwender, die nur sporadisch statistische Analysen durchführen und sich nicht tiefer mit Statistik auseinandersetzen möchten.
Support
Neben dem kommerziellen Hersteller-Support stellt IBM auf der Webseite umfangreiche kostenlose Support-Ressourcen zur Verfügung. SPSS selbst bringt eine sehr verständliche Hilfe mit, die viele Prozeduren anhand von Fallbeispielen veranschaulicht und vielfach sogar anhand animierter Fallstudien mit Beispieldatensätzen Schritt für Schritt vorstellt. Für die systematische Einarbeitung gibt es unzählige Bücher. Thematisch deckt die Literatur von der Kurzeinführung bis zu speziellen Themen, wie z.B. der Conjoint-Analyse, nahezu alles ab. Darüber hinaus finden sich im Internet zahlreiche Tutorials (beispielhaft sei die Webseite von Dr. Hans Grüner erwähnt, auf der umfassende Materialien und Video-Tutorials sowie Beispiele für die Integration mit R und Python zusammengestellt sind). Ebenfalls lang ist die Liste an unabhängigen Drittanbietern, die Unterstützung bei der Umsetzung von Projekten mit SPSS anbieten.
Angebot an Schulungen
Aufgrund des hohen Verbreitungsgrads ist auch das Angebot an Schulungen groß: IBM Training bietet einige Schulungen zu ausgewählten Themen in Zusammenhang mit SPSS an. Darüber hinaus gibt es zahlreiche private Anbieter (Suche nach „spss schulung“), deren Schulungsangebote im Vergleich zu SAS- oder STATA-Schulungen oft günstiger sind. Selbst einige Volkshochschulen haben preisgünstige SPSS-Kurse im Angebot. Zudem bieten auch fast alle Universitäten SPSS-Kurse an, die sich aber i.d.R. nur an Universitätsangehörige richten.
Vorhandene Qualifikation der Mitarbeiter*innen
In der Vergangenheit sorgte die hohe Verbreitung im universitären Bereich stets dafür, dass auch die Unternehmen mit einem steten Strom an Mitarbeiter*innen versorgt wurden, die in ihrer Ausbildung SPSS – häufig als einziges Statistik-Programm – verwendet haben. Durch den zunehmenden Kostendruck und die Weiterentwicklung insbesondere von R wird aber gerade im universitären Bereich verstärkt auf Alternativen gesetzt. Die einfache Bedienbarkeit in Kombination mit der hohen Konkurrenz auf dem Schulungsmarkt sorgt aber weiterhin dafür, dass der Schulungsaufwand für SPSS tendenziell geringer ausfällt als bei konkurrierenden Statistik-Programmen.
Stabilität/Innovativität
Der Release-Zyklus von SPSS Statistics ist mit einem Jahr moderat gewählt. STATA veröffentlicht z.B. nur alle drei Jahre eine neue Major-Release, während die R-Community dies alle sechs Monate tut. Im Vergleich zur Konkurrenz wirkten einige der jüngeren SPSS-Releases unausgereift. Die Symptome reichten dabei von Dialogfeldern mit fehlerhaften Textumbrüchen unter Mac OS X über unvollständig auf die Sprachversion angepasste Dialogfelder bis hin zu gravierenderen Problemen (wie dem Ignorieren einzelner Parameter in Dialogfeldern oder dem sporadischen Verschwinden einzelner Menüs). Im Vergleich zu SAS, dem Primus in Sachen Stabilität und Zuverlässigkeit, hat SPSS in dieser Hinsicht etwas Nachholbedarf.
Kein anderes Statistik-Programm polarisiert so stark wie SPSS: Lange Zeit genoss SPSS in vielen Bereichen quasi eine Monopolstellung. Durch R bricht dieses Monopol gerade im universitären Bereich langsam auf. Für Gelegenheitsnutzer gibt es zu SPSS kaum eine Alternative. Das Programm weiß durch einfache Bedienung, eine praxisnahe Hilfe und Prozeduren, die insbesondere Standardaufgaben im Marketing stark vereinfachen, zu überzeugen. Kritikpunkte sind – neben dem Preis der kommerziellen Versionen – vor allem die lückenhafte Unterstützung selten genutzter statistischer Methoden und die im Vergleich zur Konkurrenz geringere Stabilität. Mit der Öffnung gegenüber Python und R schlägt SPSS eine Brücke zur Open Source-Welt. Wer diese Funktionen intensiv nutzt, wird jedoch irgendwann darüber nachdenken, komplett zu Python oder R zu wechseln.
Studierenden und Mitarbeitern von Bildungseinrichtungen kommt SPSS mit günstigen Lizenzen entgegen. Wer SPSS dagegen im kommerziellen Umfeld einsetzt, muss deutlich tiefer in die Tasche greifen, weswegen auch hier immer mehr Nutzer überlegen, ob der Umstieg auf R, Python oder STATA langfristig sinnvoll sein kann. Zwar ist SPSS hinsichtlich der Bedienung optimal für Gelegenheitsnutzer, gerade in diesem Nutzungsszenario stellt sich allerdings auch verschärft die Frage nach der Wirtschaftlichkeit der Lizenz. Wie stark viele Nutzer an SPSS hängen, verdeutlicht das GNU-Projekt PSPP, welches versucht, eine freie Alternative zu SPSS zu schaffen, die die Oberfläche von SPSS imitiert. Ob dieses Projekt langfristig weitereinwickelt wird, wird die Zukunft zeigen. SPSS führt regelmäßig neue Funktionen ein, behält alte Dialogfelder jedoch bei, um unwillige Nutzer nicht zur Umgewöhnung zu zwingen. Die in den letzten Versionen implementierten Funktionen, die dem Nutzer viele Entscheidungen abnehmen und Ergebnisse z.T. bereits interaktiv aufbereitet präsentieren, schärfen das Profil von SPSS weiter.
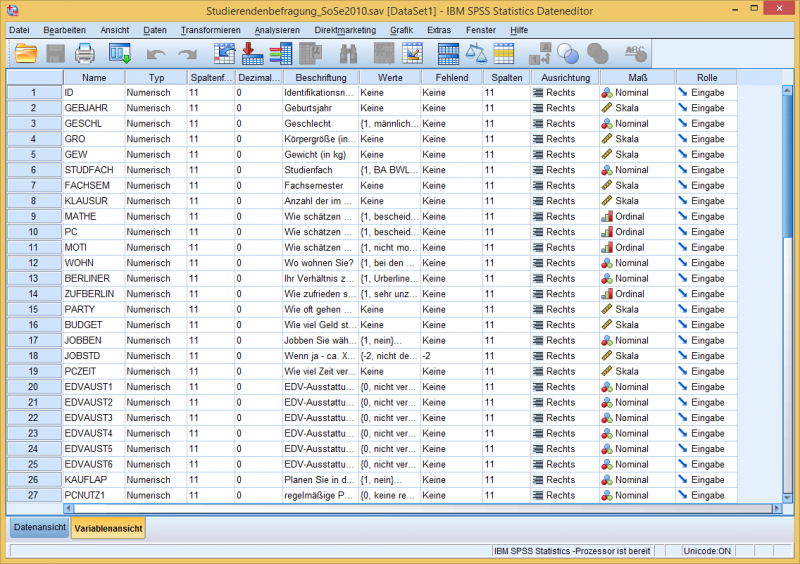 Neben der "Datenansicht" gibt es in SPSS die "Variablenansicht", in der sich u.a. das Messniveau einstellen lässt.
Neben der "Datenansicht" gibt es in SPSS die "Variablenansicht", in der sich u.a. das Messniveau einstellen lässt.
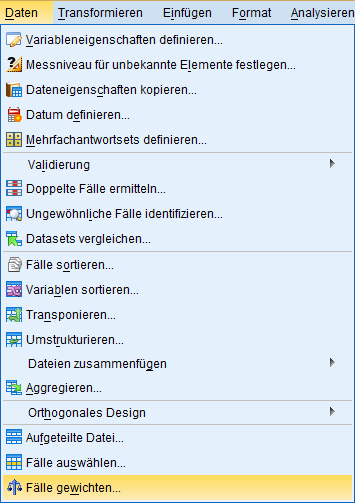 Im Menü "Daten" bündelt SPSS zahlreiche hilfreiche Funktionen, u.a. eine komfortable Filterung der Daten sowie die Fallgewichtung.
Im Menü "Daten" bündelt SPSS zahlreiche hilfreiche Funktionen, u.a. eine komfortable Filterung der Daten sowie die Fallgewichtung.
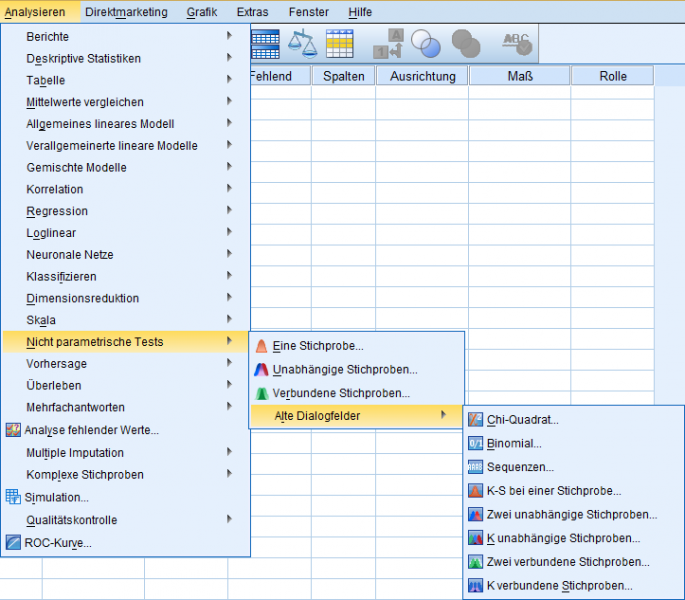 Neben den neuen Wizards für nicht-parametrische Tests sind die alten Prozeduren weiter über das Untermenü "Alte Dialogfelder" zugänglich.
Neben den neuen Wizards für nicht-parametrische Tests sind die alten Prozeduren weiter über das Untermenü "Alte Dialogfelder" zugänglich.
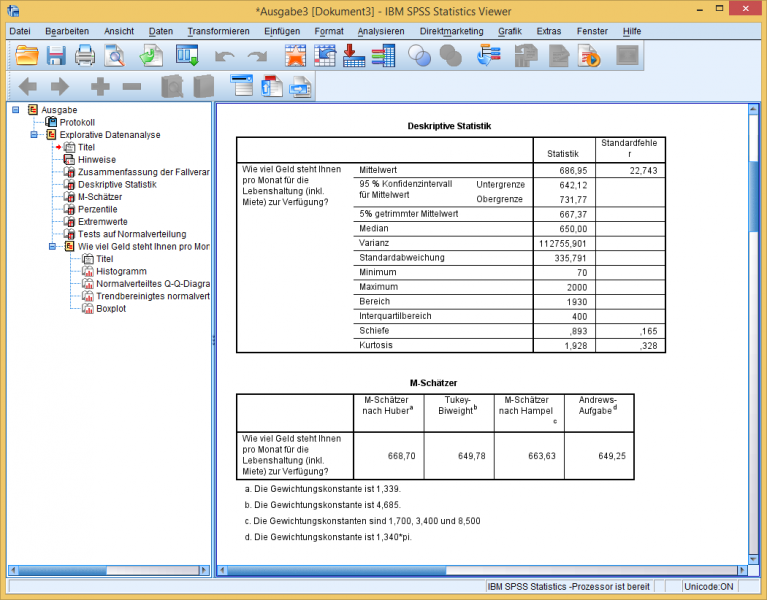 Die Funktion "Explorative Datenanalyse" ermöglicht eine schnelle Kontrolle der Daten und unterstützt auch robuste Lageparameter.
Die Funktion "Explorative Datenanalyse" ermöglicht eine schnelle Kontrolle der Daten und unterstützt auch robuste Lageparameter.
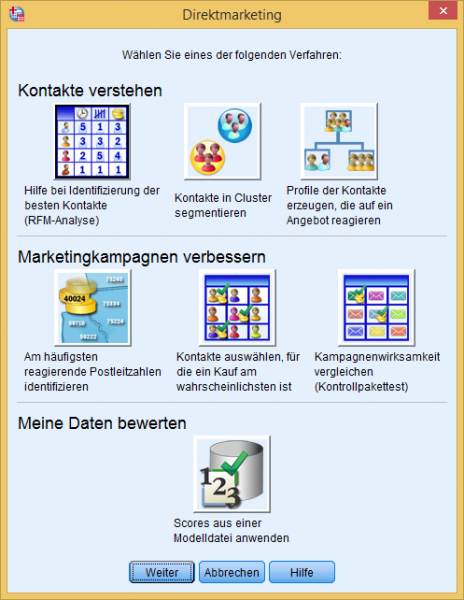 Der zum gleichnamigen Modul gehörende Dialog "Direktmarketing" bündelt für das Marketing relevante Methoden.
Der zum gleichnamigen Modul gehörende Dialog "Direktmarketing" bündelt für das Marketing relevante Methoden.
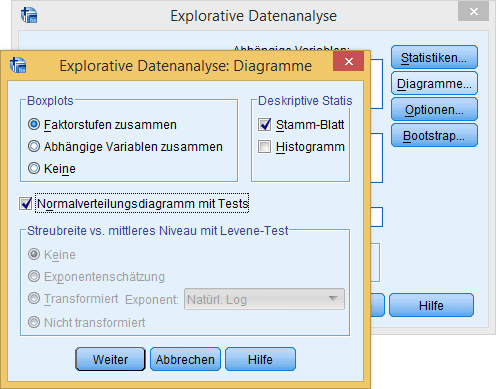 Die Tests auf Normalverteilung versteckt SPSS unter Analysieren > Deskriptive Statistiken > Explorative Datenanalyse... > Diagramme...
Die Tests auf Normalverteilung versteckt SPSS unter Analysieren > Deskriptive Statistiken > Explorative Datenanalyse... > Diagramme...
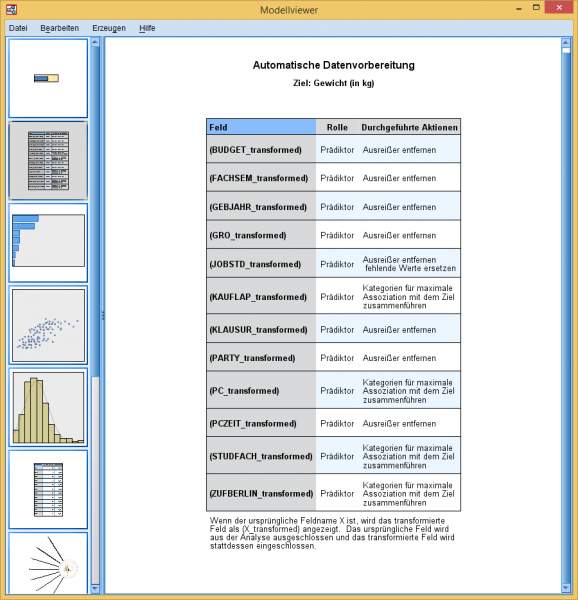 Die automatische lineare Modellierung ist ein Beispiel für eine Prozedur, die dem Nutzer Entscheidungen abnimmt und selbstständig z.B. vermeintliche Ausreißer entfernt.
Die automatische lineare Modellierung ist ein Beispiel für eine Prozedur, die dem Nutzer Entscheidungen abnimmt und selbstständig z.B. vermeintliche Ausreißer entfernt.
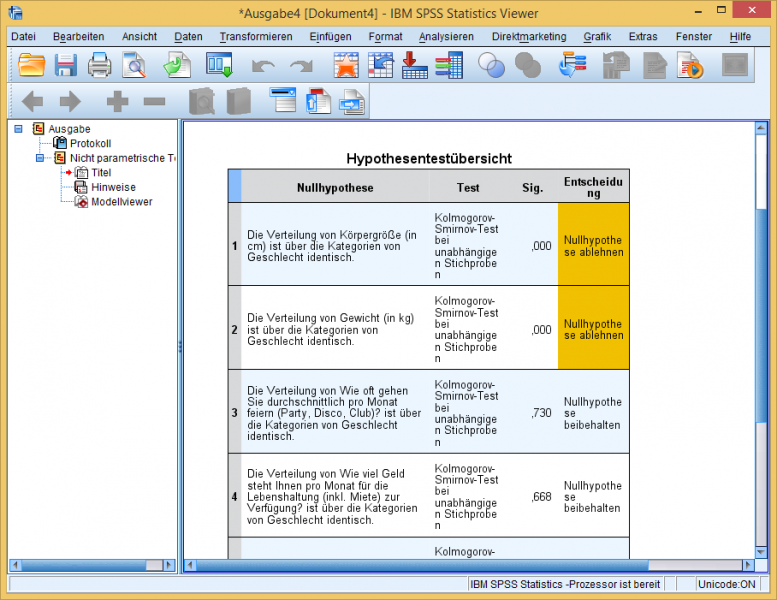 Der Output der neuen Wizards zu nicht-parametrischen Tests ist auf Testentscheidung und p-Wert reduziert, Details offenbaren sich erst nach einem Doppelkick.
Der Output der neuen Wizards zu nicht-parametrischen Tests ist auf Testentscheidung und p-Wert reduziert, Details offenbaren sich erst nach einem Doppelkick.





