Aufbau eines starken Data Science-Teams von Grund auf
Die Business-Welt verändert sich aufgrund der zunehmenden Menge und Vielfalt der verfügbaren Daten. Durch die Nutzung des in diesen Daten enthaltenen Wissens, eröffnen sich bedeutende neue Chancen - wenn man weiß, wo man suchen muss. Ein Data Science-Team trägt dazu bei, aus der Verarbeitung und Analyse dieser Rohdaten Erkenntnisse zu gewinnen, die im kompetitiven technologischen Umfeld von entscheidender Bedeutung sind.
Für viele Unternehmen kann der Aufbau eines Data-Science-Teams jedoch entmutigend sein: Das Gebiet ist technisch, die Rollen sind vielfältig und Schlagworte sind nicht klar umgrenzt. Dieser Artikel soll Ihnen dabei helfen diesen Prozess zu steuern. Es muss herausgearbeitet werden, welche Positionen vorhanden sind, welche Fähigkeiten wirklich benötigt werden und welchen Platz das Data Science-Team in der Organisation einnehmen soll. Darüber hinaus möchten wir Ihnen zeigen, wie Sie konsequent sicherstellen, dass Sie die richtigen Mitarbeiter einstellen.
Ein Data Science-Team kann aus vielen verschiedenen Fachgebieten bestehen
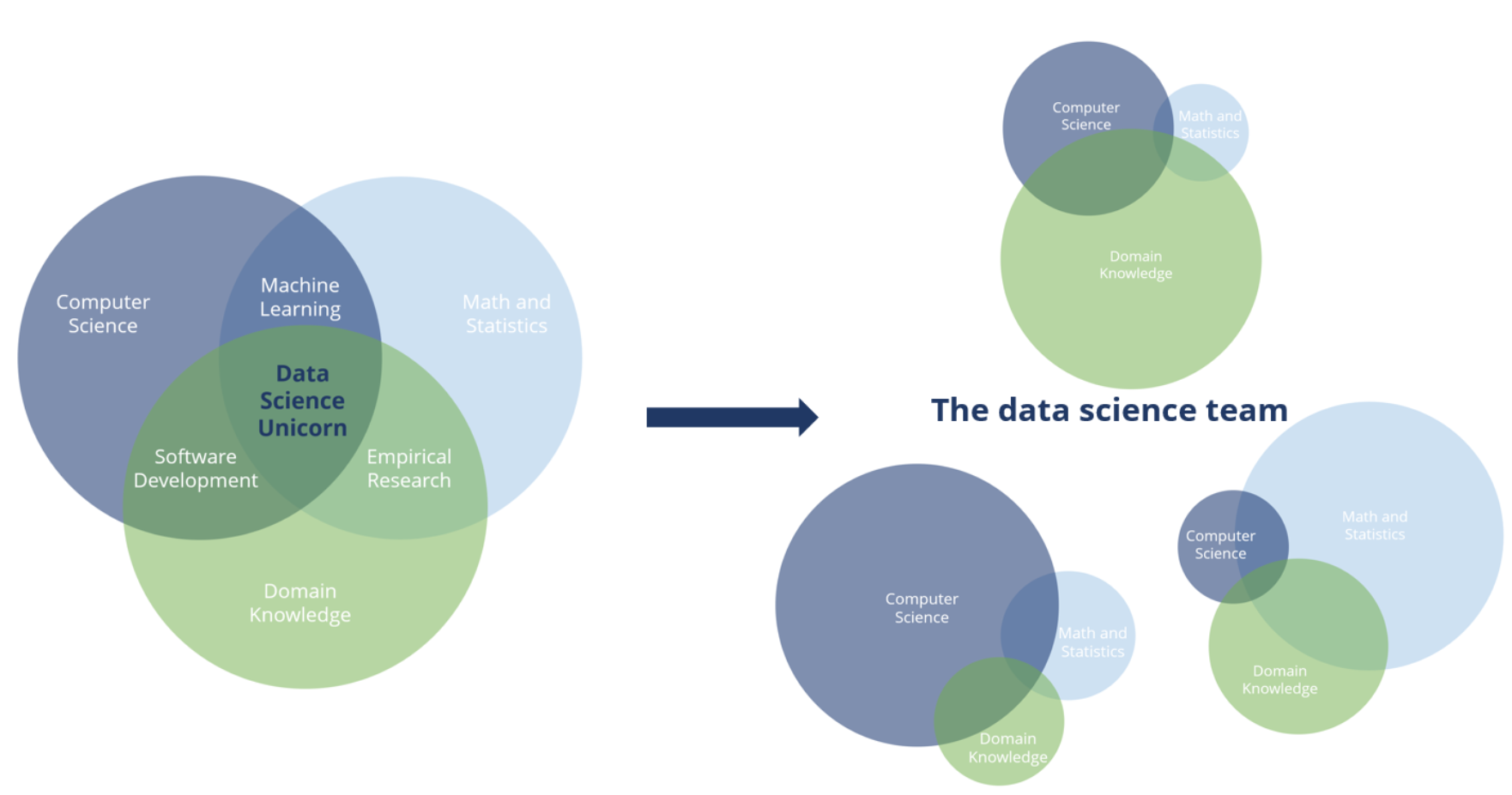
Es gibt ein weit verbreitetes Missverständnis, dass ein Data Scientist in allen möglichen Bereichen Experte sein sollte. Während Data Scientists häufig zwar über umfassende Fähigkeiten und Kenntnisse verfügen, setzen sich die Teams häufiger aus Personen mit unterschiedlichen Spezialgebieten zusammen.
Beispielsweise haben Data Engineers in der Regel einen IT-Hintergrund und konzentrieren sich auf den Aufbau der Dateninfrastruktur. Machine Learning Engineers können eine Vielzahl von Machine Learning-Modellen erstellen. Forscher oder Statistiker sind Experten für statistische Methoden und haben möglicherweise einen akademischen Hintergrund. Ein Analyst oder Visualisierungsexperte ist für die Interpretation und Präsentation der Ergebnisse verantwortlich. Data Stewards sind dafür verantwortlich, die Datenqualität, die Prozesse und einen ethischen Umgang sicherzustellen. Data Scientists verfügen häufig über eine umfassendere Kombination dieser Fähigkeiten. Und natürlich muss jemand dafür verantwortlich sein, ein Data Science-Team effektiv zu managen.
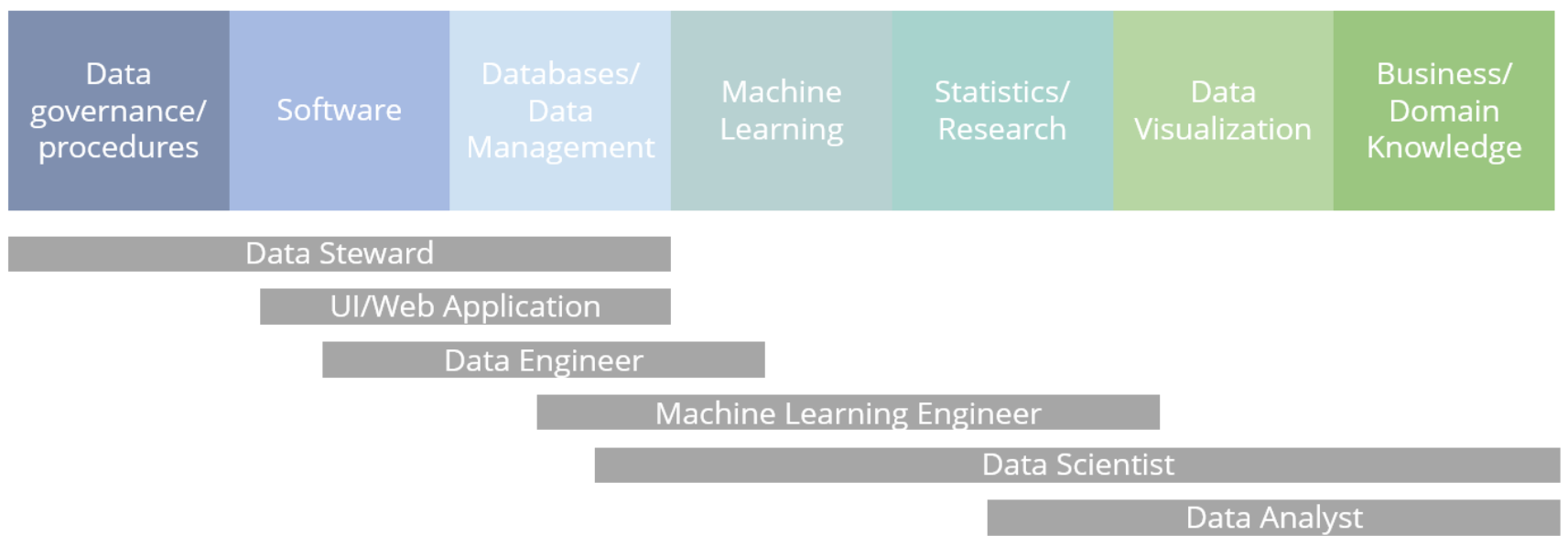
Während die Data Science Domain weiter wächst, entwickeln sich immer neue und fokussiertere Rollen. Zum Beispiel spielen DevOps Engineers und Solutions Architects eine größere Rolle, sobald das Team weiter wächst.
Jedoch sind nicht alle dieser Rollen für jedes Projekt oder Unternehmen erforderlich, aber es ist sinnvoll, dass die Mitarbeiter in Ihrem Team zumindest teilweise über Fähigkeiten in all diesen Bereichen verfügen, damit sie gemeinsam alle an sie gestellten Herausforderungen effektiv bewältigen können. Es ist unwahrscheinlich, ein “Einhorn” zu finden, das das gesamte Spektrum effektiv abdecken kann, und selbst wenn, wird es oft nicht zum besten Ergebnis führen.
Neben den technischen, rollenspezifischen Fähigkeiten wie bestimmten Programmiersprachen, statistischen Methoden oder Machine Learning-Modellen sind Soft Skills eine entscheidende - und oft unterschätzte - Notwendigkeit für leistungsstarke Data Scientists.
Zum Beispiel sind hervorragende Kommunikationsfähigkeiten - sowohl zwischen Abteilungen als auch zur Vermittlung von Ergebnissen - unerlässlich. Eine intellektuelle Neugier, eine experimentelle Denkweise und die Fähigkeit, neue Konzepte und Werkzeuge schnell zu erlernen, sind ebenfalls wichtig. Liebe zum Detail und ein Sinn für Datenqualität sind der Schlüssel. Einige Projekte erfordern möglicherweise auch Geschäftssinn oder domänenspezifische Kenntnisse.
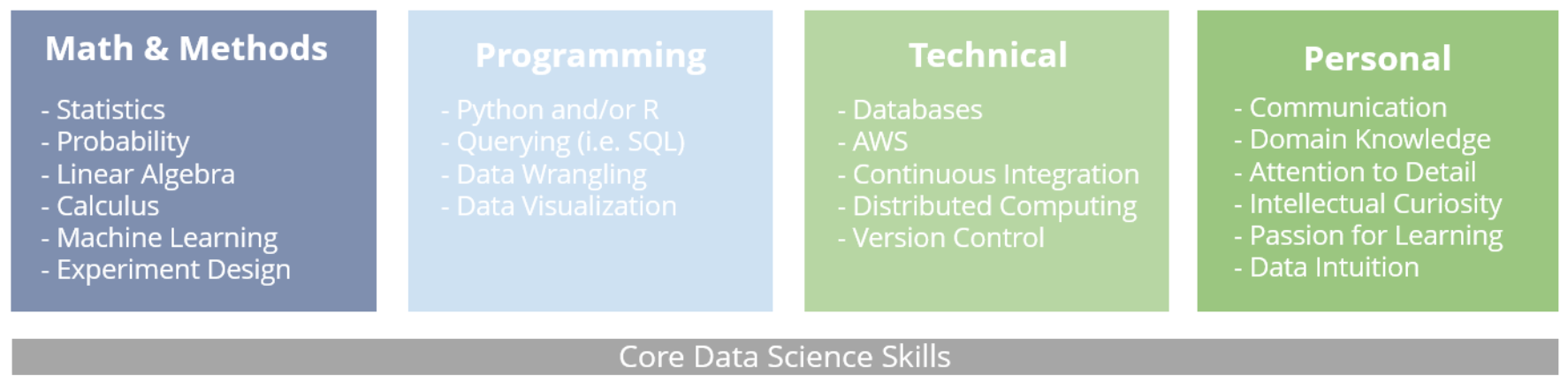
Diese Soft Skills sind je nach Projekt und Team-Struktur unterschiedlich wichtig. Das wichtigste Kriterium bei der Festlegung der zu priorisierenden Fähigkeiten sind die spezifischen Anforderungen des Unternehmens und die vom Data Science-Team zu lösenden Probleme. Sobald eine detaillierte Analyse dieser Art durchgeführt wurde, wird es einfacher, eine konkrete „Wunschliste“ von Fähigkeiten zu formulieren, die im gesamten Team vertreten sein sollten.
Die Bedeutung der Vorbereitung
Neben der Überlegung, für welche Art von Projekten das Data Science-Team verantwortlich sein wird, ist es wichtig, die Rolle zu berücksichtigen, die das Team in der Organisation selbst spielen wird. Mit den Stakeholdern im gesamten Unternehmen sollten Gespräche darüber geführt werden, was sie mit Data Science erreichen möchten, was realistisch möglich ist und mit welchen Zeitplänen zu rechnen ist. Es muss auch sichergestellt werden, dass ein organisationsweites Buy-in für den Übergang zu einem datengesteuerteren Arbeitsstil erfolgt.
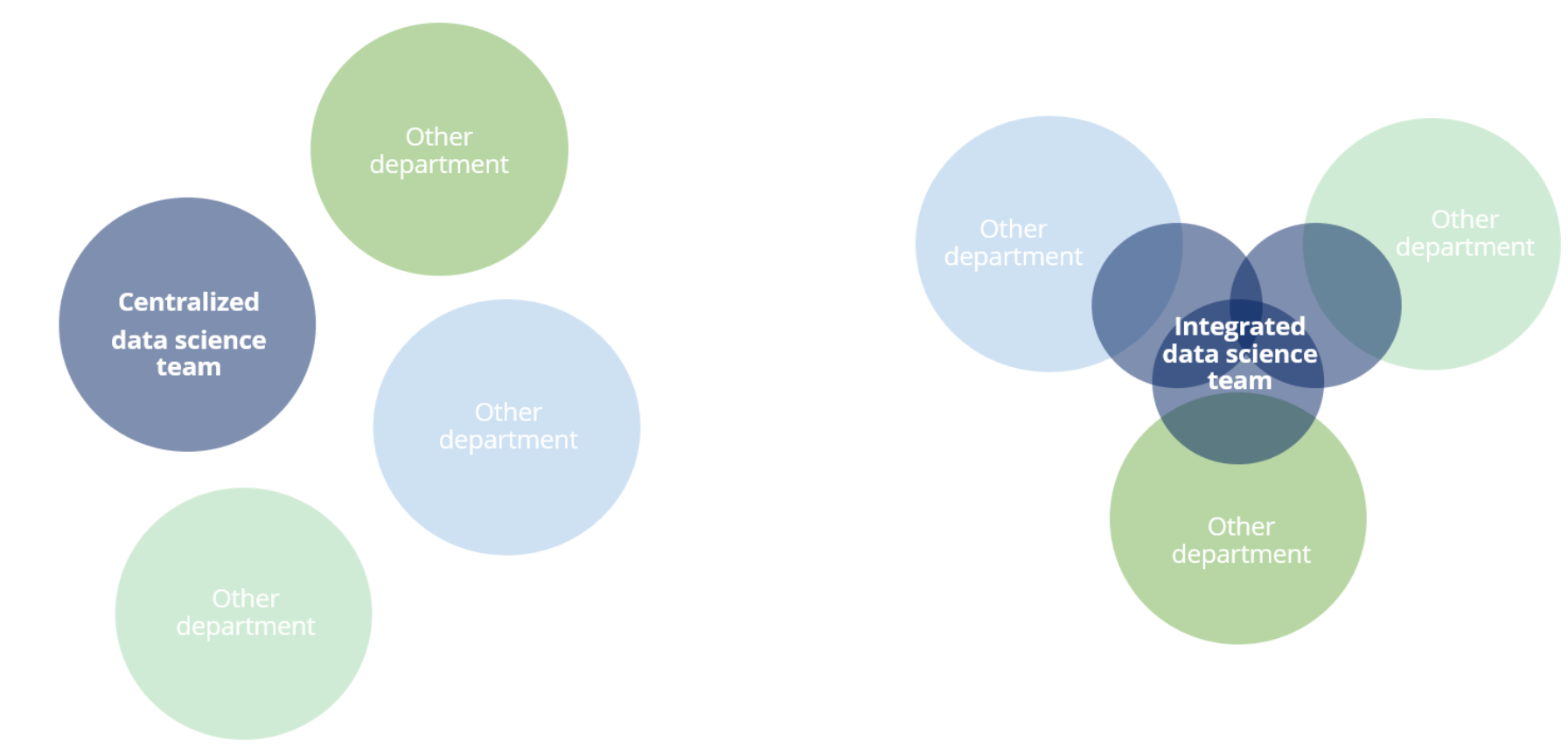
Über diese Bemühungen auf Unternehmenskulturebene hinaus müssen auch die praktischen Details der Berichtsstrukturen definiert werden, bevor ein Data Science-Team aufgenommen und integriert werden kann. Es gibt viele potenzielle Strukturen, die heute erfolgreich eingesetzt werden, z. B. eigenständige Data Science-Teams, eingebettete Teams, integriertes Team, Data Science als „interne Beratung“ und mehr.
Im Wesentlichen stellt sich die Frage, ob es sinnvoller ist, das Data Science-Team in einem einzigen Team zusammenzufassen, das an eine Person, häufig den CIO oder den Marketingleiter, berichtet, oder nicht. Die zentralisierte Option kann die Autonomie erhöhen und Systeme und Einstellungen vereinfachen, kann aber auch zu einem Team führen, das von den tatsächlichen Anstrengungen auf Unternehmensebene isoliert oder weit entfernt ist. Dies kann sogar dazu führen, dass Data Science eher als unterstützende Funktion denn als wichtiger Verbündeter und Denker für die datengetriebene Weiterentwicklung des Unternehmens angesehen wird.
Im Gegensatz dazu kann ein dezentrales Modell gewählt werden, so dass Data Scientists auf vielen Ebenen und in vielen Abteilungen eines Unternehmens vorhanden sind. Diese Personen könnten von einem zentralen Leiter oder den Abteilungen selbst angestellt werden. Dies hilft dabei, die Ziele der einzelnen Data Scientists an die Organisation als Ganzes anzupassen, möglicherweise jedoch zu Lasten der Autonomie, des Wissensaustauschs und der Karriereentwicklung der im Unternehmen verteilten Data Scientists.
Ein weiterer wichtiger Teil der Vorbereitung besteht darin, eingehend zu untersuchen, welche Daten derzeit verfügbar sind oder möglicherweise mit einigem Aufwand verfügbar sind. Über die Sicherstellung der Verfügbarkeit ausreichender Datenmengen - und vorallem der richtigen Daten - hinaus ist der eigentliche Schlüssel die Sicherstellung der Qualität. Die Erkenntnisse der Data Scientists können letztendlich nur so gut sein, wie die Daten, auf denen sie basieren.
Wenn sich herausstellt, dass die Daten noch nicht dort sind, wo sie benötigt werden, lohnt es sich möglicherweise, ein Data Science-Team zu bilden, indem Sie einen Data Engineer oder Data Steward beauftragen. Dieser hilft dann zunächst dabei, vorhandene Daten zu bereinigen und Prozesse einzurichten, um in Zukunft eine richtige Datenpipeline sicherzustellen, bevor eine Person mit analytischen Fähigkeiten hinzugezogen wird. Langfristig ist dies eine effiziente Strategie, die sicherstellen kann, dass die Erkenntnisse des Data Science-Teams die beabsichtigte Wirkung entfalten.
Die richtigen Leute einstellen
In den frühen Phasen einer stärkeren Einbindung von Data Science in Ihr Unternehmen ist es wahrscheinlich, dass es noch keine genaue Vorstellung davon gibt, auf was das Data Science-Team in Bezug auf Daten oder Anwendungsfälle genau stoßen wird. In diesem Fall ist es sinnvoll, Kandidaten mit einem breiten Kompetenzspektrum ins Auge zu nehmen, anstatt Personen mit einer starken Spezialisierung auf einem bestimmten Gebiet. Diese werden besser gerüstet sein, um neue Fähigkeiten und Werkzeuge im Beruf zu erlernen, wenn sie auf unerwartete Herausforderungen stoßen.
In diesem Sinne ist es auch ratsam, Personen mit Vorkenntnissen möglichst frühzeitig einzustellen. Während Studenten und Neuankömmlinge in der Data Science-Abteilung durchaus eine wertvolle Bereicherung für das Team darstellen können, ist es in der Anfangszeit wichtig, dass das neue Team von mindestens einem oder zwei erfahrenen Personen verankert wird.
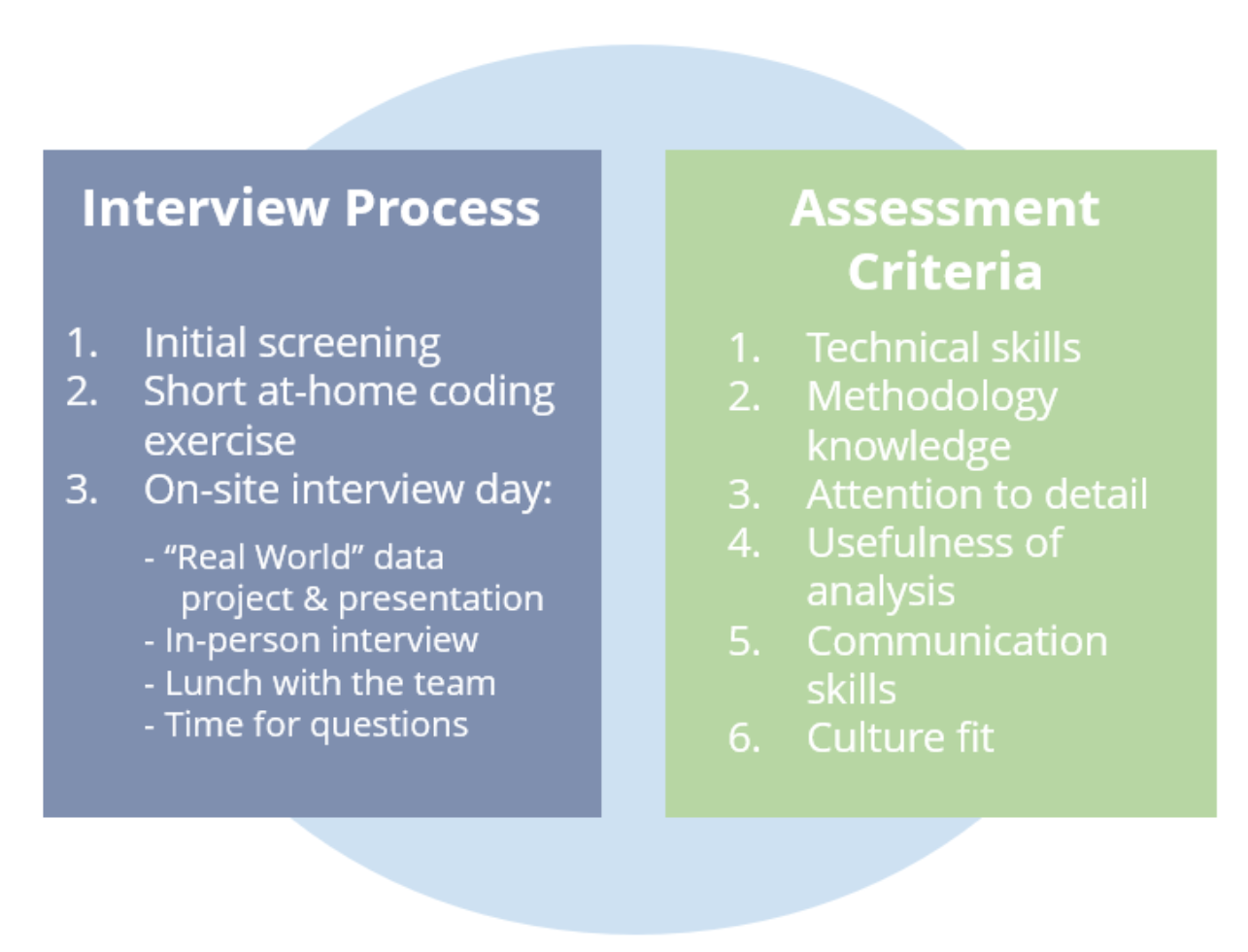
Um die richtigen Kandidaten zu finden, ist ein solider Einstellungsprozess der Schlüssel. Dies umfasst in der Regel eine erste Coding-Übung, um ein Grundniveau an technischen Fähigkeiten sicherzustellen, ein persönliches Interview, um sicherzustellen, dass sie zur Unternehmenskultur passen, und häufig ein komplexeres Datenanalyseprojekt.
Zum Beispiel können Kandidaten, die aufgrund ihres Hintergrunds und des anfänglichen Screenings besonders interessant erscheinen, zu einer Data Challenge ins Unternehmen gebracht werden. Bei der Data Challenge wird ihnen ein Datensatz zur Bearbeitung bereitgestellt, dessen Analyse eine ähnliche Herausforderung birgt, wie es im Unternehmen auftreten könnte. Die Kandidaten haben dann einen Tag Zeit, um die Daten zu untersuchen, Fragen zur Challenge zu stellen, eine Analyse zu erstellen und die Ergebnisse zu präsentieren. Auf diese Weise haben Sie die Möglichkeit, viel über die Arbeitsweise der Kandidaten zu lernen und diese wiederrum können einen Einblick in die Art der Aufgaben erhalten, für die sie zukünftig verantwortlich sein könnten und wie es ist, Teil Ihres Teams zu sein.
Da Soft Skills ein häufig unterschätzter Aspekt der Fähigkeiten sind, um im Bereich Data Science gute Leistungen zu erbringen, bietet es sich auch an, den Kandidaten für ein Probe-Projekt zu gewinnen, und so nicht nur die Arbeitsweise genauer kennenzulernen sondern auch zu schauen ob man auch auf einer persönlichen/sozialen Ebene harmoniert.
Bei der Bewertung der Leistung eines Bewerbers in einer Data Challenge sollten folgende Aspekte berücksichtigt werden:
- Technische Fähigkeiten: Entsprach der Code dem Standard (d. h. verständlich, flexibel, skalierbar usw.)?
- Methodik: Haben sie ein statistisches oder Machine Learning-Modell verwendet? Wenn ja, war es angemessen und waren die Ergebnisse solide?
- Waren sie detailorientiert? Haben sie den Datensatz untersucht, bevor sie daran gearbeitet haben?
- Wie waren ihre Kommunikationsfähigkeiten?
- Haben sie entsprechende Fragen gestellt, um ein Verständnis für den Case und die Anwendung zu erlangen?
- Waren die Ergebnisse für das Unternehmen von Nutzen?
Auch hier ist es wichtig zu bedenken, dass niemand ein Experte in allen Bereichen sein wird, aber ein solider Kandidat sollte in der Lage sein, das Problem und seinen Ansatz zu erklären und Bereiche für zukünftige Verbesserungen zu identifizieren. Wenn der Kandidat einen Mangel an Kenntnissen in einem bestimmten Bereich zugibt, ist dies wahrscheinlich positiv - die Kenntnis der Grenzen des eigenen Wissens zeigt ein realistisches Verständnis davon, wie viel auf dem Gebiet wirklich zu wissen ist, und im Idealfall den Wunsch, weiterzulernen.
Während des gesamten Aufbaus des Teams wird eine wichtige Frage sein, wie gut diese Person das Wissen und die Fähigkeiten des vorhandenen Teams erweitern oder ergänzen würde und ob sie eine neue Sichtweise bietet. Die Verschiedenartigkeit von Hintergrundwissen, Fachwissen und sogar persönlicher Erfahrung kann sich bei einer neuen Analyse als wertvoll erweisen.
Erste Schritte
Es ist wichtig, während des Aufbaus des Teams mit überschaubaren Projekten zu beginnen, sofern dies möglich ist. Die Integration von Data Science in einen vorhandenen Workflow kann beispielsweise dazu beitragen, Vertrauen in der gesamten Organisation aufzubauen, und das Data Science-Team dabei unterstützen, Lücken im Wissen, in der Datenverfügbarkeit oder internen Systemen zu identifizieren. Einige bescheidene Projekte, die inkrementelle Verbesserungen bieten, können ein wertvoller Beweis für das Konzept und die Lernmöglichkeiten sein, bevor erhebliche Zeit und Ressourcen in ein komplizierteres Projekt investiert werden. Zumal es möglich ist, dass ein solches Unterfangen scheitert, wenn sich herausstellt, dass die Baseline-Daten und -Systeme von Anfang an fehlerhaft waren.
Obwohl es zunächst überwältigend erscheinen mag, werden die Vorteile eines talentierten, vielfältigen und gut integrierten Data Science-Teams immens sein und im Kontext des schnellen und anhaltenden technologischen Wandels wahrscheinlich in den kommenden Jahren noch weiter zunehmen. Der Schlüssel liegt darin, den Fokus auf Vorbereitung und Strategie zu legen, um das Team zielgerichtet aufzubauen. Außerdem sollte beim Einstellungsverfahren immer ein Auge darauf gerichtet sein, ein in Fähigkeiten und Erfahrungen abgerundetes Data Science-Team zusammenzustellen, das ihr Geschäft mit Daten vorantreibt.