Automatisierte Excel-Reports mit Python
Dieser Artikel beschreibt, wie man Daten aus Python in eine Excel-Datei schreibt und formatiert. Excel-Reports sind ein guter Weg, um Daten oder Ergebnisse weiterzugeben, vor allem an Personen, die selbst nicht mit Python vertraut sind. Ein weiterer Vorteil ist die Möglichkeit, Reports zu automatisieren: Inhalt und Erscheinungsbild des Reports müssen nur einmal programmiert werden; danach lässt sich der Report mit minimalem Aufwand immer wieder erstellen, zum Beispiel für Teildatensätze oder täglich geupdatete Daten.
In diesem Artikel werden zunächst die wichtigsten Features separat beschrieben (z.B. das Festlegen von Spaltenbreiten und Schriftfarbe oder Verlinkungen auf andere Tabellenblätter). Im zweiten Teil wird all das in einer Excel-Datei kombiniert.
Falls Sie übrigens nach einem Template für in Python erstellte Excel-Reports suchen, schauen Sie gern in unserem öffentlichen GitHub-Repo python-excel-report vorbei.
Grundlagen
Dieser Abschnitt beschreibt, wie man einen pandas-Dataframe in eine Excel-Datei schreibt, den Namen des Tabellenblatts festlegt und Spaltenbreiten anpasst.
Zunächst erstellen wir einen einfachen, kleinen pandas-Dataframe mit den Aktienkursen einiger Unternehmen. Diese Daten schreiben wir direkt in eine Excel-Datei.
import pandas as pd
data = pd.DataFrame({
"id": [14, 82, 5],
"name": ["Cookie Corp.", "Chocolate Inc.", "Banana AG"],
"country": ["FR", "DE", "FR"],
"stock_price": [152.501, 99.00, 45.12],
})
print(data)
# id name country stock_price
#0 14 Cookie Corp. FR 152.501
#1 82 Chocolate Inc. DE 99.000
#2 5 Banana AG FR 45.120
Die Daten enthalten eine ID, den Unternehmensnamen, das Land des Unternehmenssitzes und den aktuellen Aktienpreis. Um die Daten in eine Excel-Datei zu schreiben, benötigt man lediglich die "to_excel"-Methode für pandas-Dataframes:
output_path = "stock_price_report.xlsx"
data.to_excel(output_path)
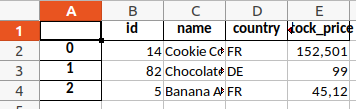
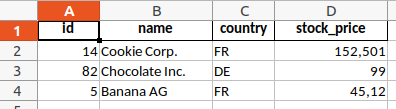
Wie man sieht, enthält der Output jedoch noch den Dataframe-Zeilenindex in der ersten Spalte. Dieser Index enthält hier jedoch keine relevante Information und ist überflüssig. Außerdem hat das Tabellenblatt den Standardnamen "Sheet1" bekommen - das wollen wir ebenfalls ändern.
data.to_excel(output_path, index=False, sheet_name="Company Report")
Offensichtlich wäre es auch sinnvoll, die Spaltenbreiten zu anzupassen. Insbesondere die Namensspalte ist deutlich zu schmal. An dieser Stelle muss ggf. noch das Paket "XlsxWriter" installiert werden. Es enthält viele nützliche Zusatzfunktionalitäten zur Formatierung von Excel-Dateien. Nach der Installation sollte Python sicherheitshalber nochmal neu gestartet werden.
Um nun die Spaltenbreiten zu verändern, muss der Aufbau des Codes noch ein wenig angepasst werden. Zuerst öffnet man die Verbindung zur Excel-Datei mittels pd.ExcelWriter, schreibt die Daten, greift nochmals auf das Tabellenblatt zu, ändert die Spaltenbreiten und schließt letztendlich die Verbindung zur Datei.
writer = pd.ExcelWriter(output_path) # Verbindung zur Excel-Datei öffnen
data.to_excel(writer, index=False, sheet_name="Company Report") # Daten schreiben
sheet_report = writer.sheets["Company Report"] # Blatt aufrufen
sheet_report.set_column(1, 1, 15) # Spaltenbreiten setzen
writer.save() # Verbindung schließen
Im Befehl sheet_report.set_column(1, 1, 15) ist das erste Argument die Anfangsspalte, das zweite die Endspalte und das dritte die Breite für all diese Spalten. Im Beispiel haben wir lediglich die Spalten "1 bis 1" auf eine Breite von 15 gesetzt. Da die Indizierung bei 0 beginnt, ist Spalte 1 natürlich die zweite Spalte, welche den Unternehmensnamen enthält.
Textformatierung
Dieser Abschnitt beschäftigt sich mit der Anpassung von Textfarbe, Schriftart, Textgröße, Zahlenformat einer Zelle und damit, wie man Spaltenumbrüche in Zellen zulässt.
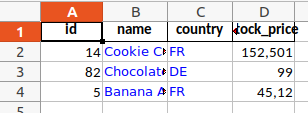
Um den Text einer Zelle zu formatieren, brauchen wir zunächst einen Dictionary mit den Formatierungsdetails, den wir dann an die Excel-Methoden weiterreichen können. Zum Beispiel:
custom_format_dict = {
"valign": "vcenter", # Zentrierter Text
"font": "PT Sans", # Schriftart
"size": "10", # Textgröße
"font_color": "blue", # Textfarbe
}
Um diesen Dictionary zu verwenden, muss man erst auf das sogenannte "Workbook" zugreifen und den Dictionary dort der Liste verfügbarer Formatierungen hinzufügen. Danach lässt er sich auf das Tabellenblatt anwenden.
writer = pd.ExcelWriter(output_path)
data.to_excel(writer, index=False, sheet_name="Company Report")
sheet_report = writer.sheets["Company Report"]
workbook = writer.book # Workbook in einem eigenen Objekt speichern
custom_format = workbook.add_format(custom_format_dict) # Dem Workbook das neue Format hinzufügen
sheet_report.set_column(first_col=1, last_col=2, cell_format=custom_format) # Neues Format für Spalten 1 und 2 verwenden
writer.save()
Um Zeilenumbrüche innerhalb von Zellen zuzulassen, braucht man nur einen Eintrag für "text_wrap" im Formatierungs-Dictionary, zum Beispiel:
custom_format_dict = {
"font": "PT Sans",
"text_wrap": True,
}
Vielleicht haben Sie schon gemerkt, dass der Aktienpreis der Cookie Corp. drei Nachkommastellen hat, der von Chocolate Inc. gar keine, und der der Banana AG zwei. Es würde besser aussehen, für alle Unternehmen genau zwei Nachkommastellen anzuzeigen. Das lässt sich mit dem Argument "num_format" umsetzen:
writer = pd.ExcelWriter(output_path)
data.to_excel(writer, index=False, sheet_name="Company Report")
sheet_report = writer.sheets["Company Report"]
workbook = writer.book
num_format = workbook.add_format({"num_format": 0x02})
sheet_report.set_column(first_col=3, last_col=3, cell_format=num_format)
writer.save()
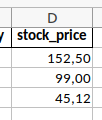
Übrigens wurde der Wert der Cookie Corp. dabei nicht gerundet - nur der angezeigte Wert wurde gerundet. Das lässt sich mit einem Klick auf die Zelle nachvollziehen. Somit gehen keine Informationen verloren.
Datumsangaben lassen sich auf dieselbe Weise formatieren, z.B. mit dem Format "yyyy-mm-dd".
Erscheinungsbild der gesamten Tabelle
Thema dieses Abschnitts ist die Formatierung der Daten als Ganzes: Formatierung als Tabelle, Einfrieren der ersten Zeile bzw. Spalte sowie das Hinzufügen von Multiheadern.
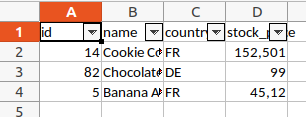
Wenn man die Daten als Tabelle formatiert, lassen sich danach die Daten direkt nach jeder Spalte filtern oder sortieren. Dazu muss die add_table-Methode auf das Tabellenblatt angewendet werden. Außerdem ist es notwendig, alle Spaltennamen nochmal zu schreiben, weil sie andernfalls mit "Column1", "Column2" usw. überschrieben werden.
writer = pd.ExcelWriter(output_path)
data.to_excel(writer, index=False, sheet_name="Company Report")
sheet_report = writer.sheets["Company Report"]
sheet_report.add_table(
first_row=0, # Tabelle beginnt in der ersten Zeile (die Spaltennamen); kein zusätzlicher Tabellenkopf darüber
first_col=0, # Tabelle beginnt in der ersten Spalte
last_row=data.shape[0], # Alle Zeilen inkl. Zeile mit Spaltennamen
last_col=data.shape[1] - 1, # Alle Zeilen (jedoch ohne Zeilennamen oder Zeilenindizes)
options={"columns": [{"header": col} for col in data.columns]}, # Spaltennamen erneut setzen
)
writer.save()
Wenn man in einer längeren Tabelle herunterscrollt, sind die Spaltennamen schon bald nicht mehr sichtbar, sodass sich der Inhalt nur noch schwer lesen lässt. Die Lösung: Die erste(n) Zeile(n) oder Spalte(n) der Tabelle lassen sich fixieren.
writer = pd.ExcelWriter(output_path)
data.to_excel(writer, index=False, sheet_name="Company Report")
sheet_report = writer.sheets["Company Report"]
sheet_report.freeze_panes(row=1, col=0) # Erste Zeile fixieren, keine Spalten fixieren
writer.save()
Bei unseren kurzen Beispieldaten ist das natürlich nicht notwendig, aber der Effekt lässt sich trotzdem durch Herunterscrollen in der Datei nachvollziehen.
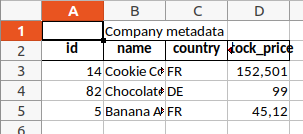
Ein Multiheader ist eine Zelle, die über mehrere Zellen reicht. Zum Beispiel möchte man vielleicht eine breite Zelle über "name" und "country", die diese beiden Zellen gemeinsam als "Company metadata" markiert. Mithilfe der Methode merge_range führen wir alle Zellen in Zeile 0 und Spalten 1 bis 2 zusammen und schreiben den gewünschten Text hinein:
writer = pd.ExcelWriter(output_path)
data.to_excel(writer, index=False, sheet_name="Company Report", startrow=1) # Erste Zeile überspringen
sheet_report = writer.sheets["Company Report"]
sheet_report.merge_range(first_row=0, last_row=0, first_col=1, last_col=2, data="Company metadata")
writer.save()
Mehrere Tabellenblätter
In diesem Abschnitt erstellen wir eine Datei mit mehreren Tabellenblättern, legen ein Standardformat für alle Blätter fest und erstellen anklickbare Links zwischen den Blättern.
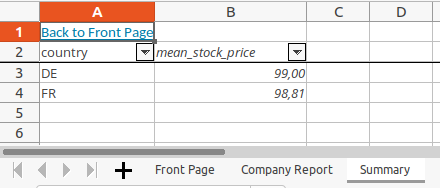
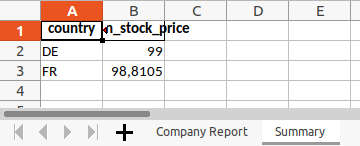
Um mit mehreren Blättern zu arbeiten, berechnen wir zuerst einen zweiten Beispieldatensatz. Er enthält den mittleren Aktienpreis pro Land:
summary = data.groupby("country", as_index=False)["stock_price"].agg("mean")
summary = summary.rename(columns={"stock_price": "mean_stock_price"})
print(summary)
# country mean_stock_price
#0 DE 99.0000
#1 FR 98.8105
Tatsächlich steht bereits alles zur Verfügung, um zwei Tabellenblätter in einer Datei zu erstellen:
writer = pd.ExcelWriter(output_path)
data.to_excel(writer, index=False, sheet_name="Company Report") # Erstes Blatt
summary.to_excel(writer, index=False, sheet_name="Summary") # Zweites Blatt
writer.save()
Es wäre umständlich, die Formatierung jedes Blatts oder sogar jeder Zelle einzeln anzupassen. Zum Glück kann man die Standard-Schriftart usw. für das ganze Dokument festlegen, indem man das erste Format im Workbook verändert.
writer = pd.ExcelWriter(output_path,
datetime_format="%Y%m%d") # Standard-Datumsformat setzen
workbook = writer.book
workbook.formats[0].set_font("Open Sans") # Standard-Schriftart des ersten Eintrags (Eintrag 0) modifizieren
workbook.formats[0].set_font_size("12")
workbook.formats[0].set_font_color("#2D0081")
data.to_excel(writer, index=False, sheet_name="Company Report")
summary.to_excel(writer, index=False, sheet_name="Summary")
writer.save()
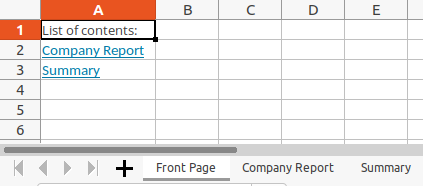
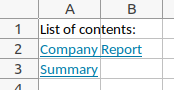
Fügen wir nun ein neues Tabellenblatt hinzu mit einem Inhaltsverzeichnis und Hyperlinks zu allen anderen Blättern. Dazu erstellen wir zuerst einen Dictionary, dessen Keys die Zellen sind, in denen der Link stehen wird, und dessen Valus die Namen der verlinkten Tabellenblätter enthalten:
front_link_dict = {"A2": "Company Report", "A3": "Summary"}
Zuerst öffnen wir wieder die Verbindung zur Excel-Datei. Dann erstellen wir die Inhaltsseite und loopen über den Dictionary, um die Links in die Zellen zu schreiben. (Hier ist übrigens erkennbar, dass man auch ohne einen pandas-Dataframe Daten in eine Excel-Datei schreiben kann.) In diesem Fall ist der Linktext identisch mit dem verlinkten sheet_name - das könnte natürlich auch anders sein. Am Ende erstellen wir noch die anderen beiden Blätter und speichern die Datei.
writer = pd.ExcelWriter(output_path, datetime_format="%Y%m%d")
workbook = writer.book
sheet_front_page = workbook.add_worksheet("Front Page")
sheet_front_page.write("A1", "List of contents:")
for column, sheet_name in front_link_dict.items():
sheet_front_page.write_url(column, "internal:{}!A1:A1".format(sheet_name), string=sheet_name)
data.to_excel(writer, index=False, sheet_name="Company Report")
summary.to_excel(writer, index=False, sheet_name="Summary")
writer.save()
Die Summe der Teile
In diesem Abschnitt kombinieren wir alle oben beschriebenen Features. Wir nutzen diese Gelegenheit, um einige Funktionalitäten in wiederverwendbare Funktionen zu packen. Außerdem fügen wir den beiden Blättern mit den Daten noch Links hinzu, um zurück auf die Inhaltsseite zu kommen, sodass man komfortabel in der Datei hin und her springen kann.
import pandas as pd
# Daten vorbereiten
data = pd.DataFrame({
"id": [14, 82, 5],
"name": ["Cookie Corp.", "Chocolate Inc.", "Banana AG"],
"country": ["FR", "DE", "FR"],
"stock_price": [152.501, 99.00, 45.12],
})
summary = data.groupby("country", as_index=False)["stock_price"].agg("mean")
summary = summary.rename(columns={"stock_price": "mean_stock_price"})
output_path = "website/blog/python_excel_reporting/report.xlsx"
# Standardformat für ganzes Dokument setzen
writer = pd.ExcelWriter(output_path, datetime_format="%Y%m%d")
workbook = writer.book
workbook.formats[0].set_font("Open Sans")
workbook.formats[0].set_font_size("10")
workbook.formats[0].set_font_color("#3b3b3b")
# Startseite mit Inhaltsverzeichnis
cover_link_dict = {"A2": "Company Report", "A3": "Summary"}
sheet_front_page = workbook.add_worksheet("Front Page")
sheet_front_page.write("A1", "List of contents:")
sheet_front_page.set_column(0, 0, 15)
for column, sheet_name in cover_link_dict.items():
sheet_front_page.write_url(column, "internal:{}!A1:A1".format(sheet_name), string=sheet_name)
# Beide Tabellenblätter mit Daten befüllen
# Hinweis: Beginn in zweiter Zeile (Index 1), um Platz für Multiheader und Links zu lassen
data.to_excel(writer, index=False, sheet_name="Company Report", startrow=1)
sheet_report = writer.sheets["Company Report"]
summary.to_excel(writer, index=False, sheet_name="Summary", startrow=1)
sheet_summary = writer.sheets["Summary"]
# Links zurück zur Inhaltsseite hinzufügen
def link_to_front_page(sheet):
"""
Put a clickable link to the Front Page to the first cell of a sheet.
:param sheet: object of class xlsxwriter.worksheet.Worksheet
"""
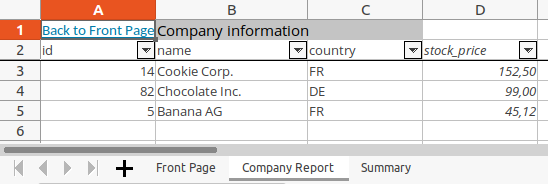
sheet.write_url("A1", "internal:{}!A1:A1".format("Front Page"), string="Back to Front Page")
link_to_front_page(sheet_report)
link_to_front_page(sheet_summary)
# Zahlenformat anpassen
custom_format_dict = {
"font": "Open Sans",
"italic": True,
"font_size": 10,
"font_color": "#3b3b3b",
"num_format": 0x02, # immer zwei Nachkommastellen anzeigen
}
custom_format = workbook.add_format(custom_format_dict)
sheet_report.set_column(3, 3, cell_format=custom_format)
sheet_summary.set_column(1, 1, cell_format=custom_format)
# Formatierung als Tabelle
def format_as_table(sheet, df):
"""
Format the data in a worksheet as table, starting in the second row
:param sheet: object of class xlsxwriter.worksheet.Worksheet
:param df: data frame with the original data that is in the sheet. Required to write the column names into the
table and to determine the required table size.
"""
sheet.add_table(
first_row=1,
first_col=0,
last_row=df.shape[0],
last_col=df.shape[1] - 1,
options={"columns": [{"header": col} for col in df.columns]},
)
format_as_table(sheet_report, data)
format_as_table(sheet_summary, summary)
# Spaltenbreiten anpassen
def set_column_widths(sheet, col_width_dict):
"""
Change column widths for selected columns of a given sheet. All other columns remain unchanged.
:param sheet: object of class xlsxwriter.worksheet.Worksheet
:param col_width_dict: dictionary with the columns widths where the keys are the column indices and the values are
the column widths, e.g. {0: 10, 5: 25}
"""
for col_index, width in col_width_dict.items():
sheet.set_column(col_index, col_index, width)
set_column_widths(sheet_report, {0: 15, 1: 20, 2: 15, 3: 15})
set_column_widths(sheet_summary, {0: 15, 1: 20})
# Tabellenkopf fixieren
def freeze_first_2_rows(sheet):
"""
Freeze header (first to rows) of a sheet, such that they remain visible when scrolling down in the table.
:param sheet: object of class xlsxwriter.worksheet.Worksheet
"""
sheet.freeze_panes(row=2, col=0)
freeze_first_2_rows(sheet_report)
freeze_first_2_rows(sheet_summary)
# Multiheader im Report-Blatt hinzufügen
multiheader_format_dict = {
"font": "Open Sans",
"bg_color": "#c4c4c4",
"valign": "vcenter",
}
multiheader_format = workbook.add_format(multiheader_format_dict)
sheet_report.merge_range(
first_row=0,
last_row=0,
first_col=1,
last_col=2,
data="Company information",
cell_format=multiheader_format,
)
writer.save()