MariaDB-Monitor
MariaDB ist aktuell die am schnellsten wachsende Open-Source-Datenbanklösung. Sie wird hauptsächlich von der MariaDB Corporation entwickelt und ist ein Fork von MySQL. Mittlerweile bietet das Datenbankverwaltungssystem mit seinen diversen kostenfreien Features vieles, was MySQL nicht oder nur kostenpflichtig zur Verfügung stellt (z.B. eine Speicher-Engine zur performanten Verarbeitung von riesigen Datenmengen; ein Datenbank-Proxy zur sicheren und hoch-verfügbaren Verwaltung skalierbarer Installationen u.v.m.). Im Gegensatz zu MySQL verfügt MariaDB jedoch nicht über einen eigenen Client wie die Workbench. Eine gute kostenfreie Alternative stellt HeidiSQL dar, jedoch verfügt diese über kein Dashboard, welches z.B. die Funktionsweise des Servers darstellt und damit Optimierungsentscheidungen erleichtert.
Inhalt des vorliegenden Beitrags
- Der Hintergrund des MariaDB-Monitors
- Die Funktionen des MariaDB-Monitors
- Die Installation des MariaDB-Monitors
Die Idee zur Entwicklung einer MariaDB-Monitoring-App
Für das Berichten und Monitoren von MariaDB existieren einige Tools, die jedoch z.T. kostenpflichtig sind. Dazu gehört z.B.:
- MONyog (kostenpflichtig)
- Percona Toolkit (kostenfrei)
- AppDynamics (kostenpflichtig, SAS-Lösung)
Nachteil der Lösungen ist, dass sie nur eine eingeschränkte Flexibilität bieten, teilweise kostenpflichtig sind oder erforderlich machen, dass unternehmensinterne Daten nach außen gegeben werden. So entstand die Idee zur Entwicklung einer eigenen Lösung, mit der unsere firmeninterne Datenbankinfrastruktur überwacht und optimiert werden kann.
Für die Umsetzung der Lösung wurde die OpenSource-Statistikumgebung R in Verbindung mit dem Shiny-Package gewählt. Eine erste funktionsfähige Version wurde auf Github veröffentlicht und wird an dieser Stelle vorgestellt. Es sind zahlreiche Verbesserungen und zusätzliche Features geplant. Da das Projekt jedoch geringe Priorität besitzt, wird es parallel zum Tagesgeschäft und mit verhältnismäßig wenig Ressourcen vorangetrieben. Wir freuen uns über jede Beteiligung an der Weiterentwicklung.
Die Herausforderung
Unsere Datenbankserver werden ausschließlich für klassische Data-Warehouse-Szenarien verwendet. Problemstellungen, die sich aus der Datenspeicherung für Webservices ergeben, treffen bei uns nicht zu. Vordergründig sind Probleme, die sich aus der Verarbeitung und Abfrage großer Datenmengen ergeben, z.B. resultierend aus BI und OLAP Anwendungen. Der MariaDB-Monitor richtet sich nach diesen Zielen, ist jedoch mit Kenntnissen in der Programmiersprache R leicht anpassbar.
Die Funktionen des MariaDB-Monitors
Der MariaDB-Monitor gliedert sich in drei Bereiche: Ein großer Bereich in der Mitte der App visualisiert die angeforderten Informationen. Über die linke Seitenleiste lassen sich dafür verschiedene Themengebiete auswählen. Der dritte Bereich befindet sich in der oberen rechten Ecke. Es handelt sich dabei um ein Benachrichtigungsfenster, das über Auffälligkeiten informiert.
Seitenleiste - Übersicht über die Inhalte
Die Seitenleiste des MariaDB-Monitors bietet Zugang zu einer Reihe von Informationen zum Status und zur Funktionsweise des MariaDB-Servers.
Im oberen Teil der Seitenleiste befindet sich ein Selektor zur Auswahl eines Datenbank-Servers. Standardmäßig wird der in der Konfiguration (config.file) angegebene Datenbankserver ausgewählt. Befindet sich dieser in einer Master-Slave-Umgebung, sind sämtliche verbundene Slaves über den Selektor auswählbar. Voraussetzung für einen Wechsel des Datenbankservers ist, dass alle über den Port 3306 verfügbar sind. Zudem muss der Datenbankzugang (Account) auf allen Datenbankservern identisch sein.
Unterhalb des Selektors befindet sich ein Block mit allgemeinen Status-Informationen zum ausgewählten Datenbank-Server. Diese umfassen u.a. die Server-Laufzeit, die Anzahl der aktuellen Prozesse und die aktuelle Buffer-Größe. Alle Kennzahlen wurden über eine Einrückung nach rechts sowie über grüne Icons hervorgehoben. Sie verlinken auf Tabs mit detaillierten Informationen.
Unterhalb des Kennzahlen-Blocks befindet sich ein Verzeichnis aller Seiten des MariaDB-Monitors. Eine Interaktion mit den Links bietet Zugang zu detaillierteren Server-Informationen. Dazu gehört:
- MariaDB Status: Allgemeine Informationen zur Funktionsweise des Datenbankservers.
- Statement Analysis: Detaillierte Informationen zu den ausgeführten Datenbank-Abfragen.
- Index Statistics: Informationen zur Verwendung und der Qualität der Datenbank-Indizes.
- User Statistics: Allgemeine Informationen zu den Verbindungen der Datenbank-Nutzer.
- Events: Informationen zu den eingerichteten Server-Ereignissen.
- InnoDB Status Output: Übersicht zu den operationellen Informationen der InnoDB Speicher-Engine.
- Allocated Mem: Übersicht über den zugewiesenen Arbeitsspeicher.
- Server-Variables: Übersicht über sämtliche Server-Variablen.
- MaxScale: Informationen zur Funktionsweise von MaxScale (falls vorhanden).
Die letzte Option „Configuration“ ermöglicht die Konfiguration des MariaDB-Monitors, z.B. können die Grenzwerte für das Einfärben von Werten angepasst werden. Im Folgenden wird der Inhalt der einzelnen Seiten kurz beschrieben.
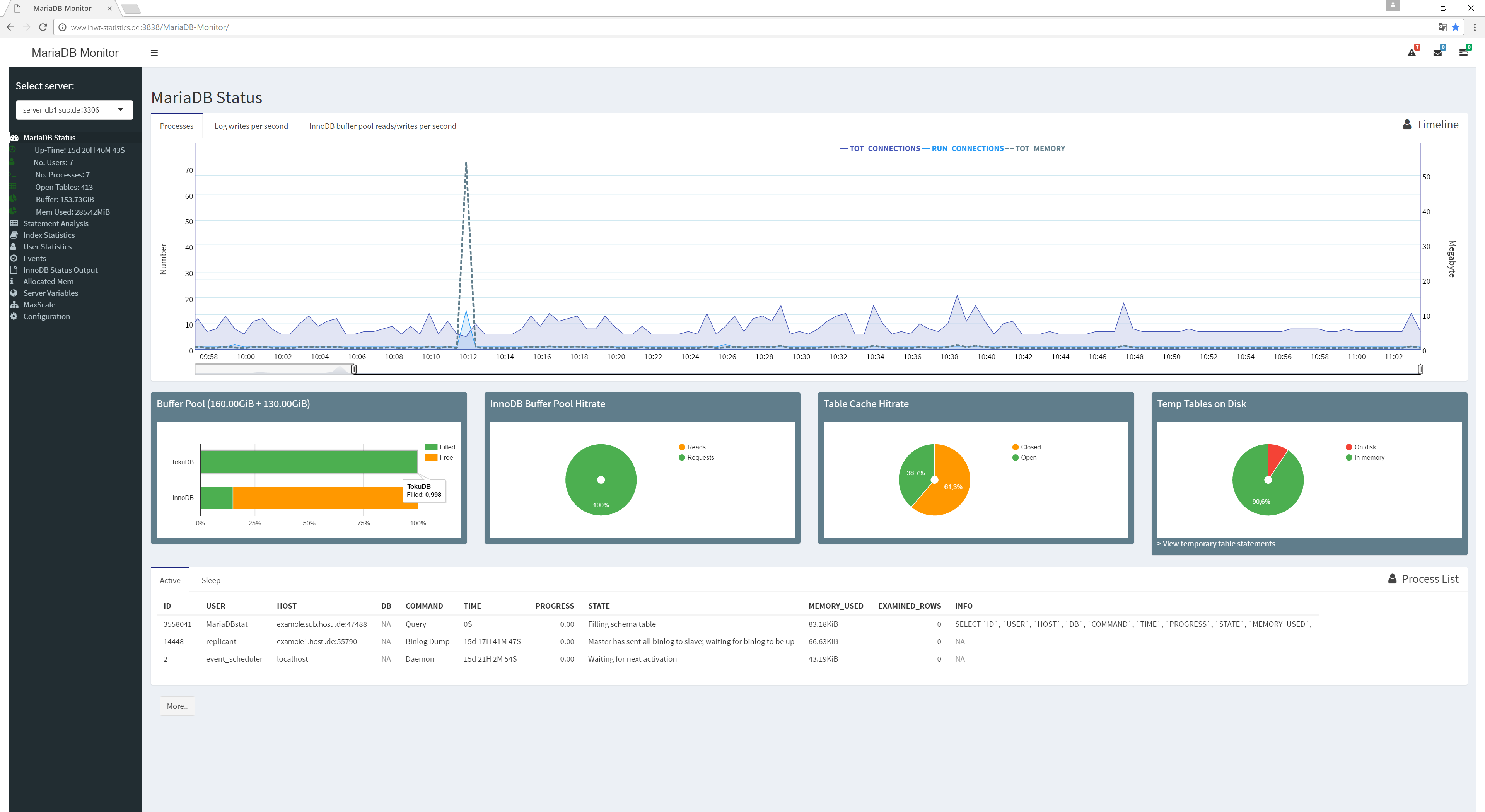
MariaDB Status - die Startseite der App
Der MariaDB Status ist gleichzeitig die Startseite des MariaDB-Monitors und beinhaltet allgemeine Informationen zur Funktionsweise des Datenbankservers. In der oberen Grafik wird die Gesamtzahl der Client-Verbindungen (bzw. Threads), die Anzahl aktiver Verbindungen sowie der dafür verwendete Arbeitsspeicher angezeigt. Über den Selektor des umliegenden Tabs erhält der Nutzer die Möglichkeit, Diagramme zu Log-Prozessen und Buffer Pool-Prozessen anzufordern.
Unter dem Diagramm befinden sich vier Abschnitte mit Kreisdiagrammen bzw. Balkendiagrammen zu wichtigen Key Performance Indikatoren (KPIs):
- Buffer Pool: Dieses Diagramm zeigt den Füllstand des Buffers. Optimaler Weise sollte er nahe 100% stehen. Wird neben der InnoDB-Speicher-Engine auch die
- TokuDB-Engine verwendet, erweitert sich die Grafik automatisch.
- InnoDB Buffer Pool Hitrate: Anteil der durch den Buffer beantworteten Anfragen.
- Table Cache Hitrate: Anteil der offenen Tabellen an allen seit dem letzten Neustart geöffneten Tabellen.
- Temp Tables on Disk: Anteil der temporären Tabellen, die im und außerhalb des Arbeitsspeicher angelegt wurden.
Unterhalb der vier Abschnitte folgt eine Zusammenstellung der wichtigsten Server-Variablen und dem zugehörigen Status. Sie lassen sich über den Button „More“ aufrufen und sind thematisch gruppiert.
Statement Analysis - wie der Server Abfragen beantwortet
Tiefergehende Informationen für eine Server-Optimierung bietet das Tab „Statement Analysis“. Datenbankabfragen haben maßgeblichen Einfluss auf die Serverauslastung und sollten unter verschiedenen Gesichtspunkten überwacht werden. Im oberen Teil der Seite befinden sich allgemeine Informationen und Links zur Abfrageoptimierung sowie zur generellen Server-Optimierung. Darunter befindet sich eine Tabelle mit fünf Reitern:
By execution frequency
Diese Tabelle zeigt die häufigsten Abfragen. Die durchschnittliche Laufzeit wird dabei über zwei Grenzwerte farblich hervorgehoben (grau, orange, rot). Generell ist zu vermeiden, dass unter den häufigsten Abfragen Laufzeiten im orangenen oder roten Bereich existieren. Optimierungsmaßnahmen lassen sich z.B. auf Basis des SQL-Statements (Spalte „query“) und/oder der Information, ob ein Table-Scan durchgeführt wurde (Spalte „full_scan“) treffen. Wurde ein Table-Scan durchgeführt, ist die Tabellen- und Datenbankstruktur zu prüfen. Indizes können ggf. helfen, den Table-Scan zu vermeiden. Auch der SQL-Code ist zu prüfen und ggf. zu optimieren. So zeigt z.B. das Ausführen der Abfrage auf der Datenbank mit einem vorangestelltem „explain“ den Ausführungsplan der Query-Engine.
Sollten wenige Änderungen an den Daten stattfinden und häufig identische Abfragen gegen den Server laufen, kann ggf. die Nutzung des Query-Caches die Laufzeiten reduzieren.
Die Anzahl der ausgegebenen SQL-Statements und die Grenzwerte für das Einfärben der Werte lassen sich im Bereich „Configuration“ anpassen.
By runtimes in 95th percentile
Diese Tabelle listet die langsamsten Abfragen. Besonderes Augenmerk sollten Abfragen mit häufiger Ausführung erhalten (Spalte „exec_count“). Einen ersten Zugang zu den Ursachen einer zu langen Ausführungszeit kann der SQL-Code (Spalte „query“) geben. Dieser lässt sich für eine detailliertere Untersuchung mit einem vorangestellten „explain“ auf der Datenbank ausführen. Mit den damit gewonnenen Informationen kann die Abfrage oder die Tabelle optimiert werden. Eine weitere Lösung kann u.U. eine Aggregationstabelle darstellen.
Die Grenzwerte für die Einfärbung der Werte in der Spalte „avg_latency“ lassen sich ebenfalls im Bereich „Configuration“ anpassen.
Statements with full table scan
Diese Tabelle listet Abfragen mit mindestens einem Table-Scan. Table-Scans führen in der Regel zu längeren Laufzeiten, da jede einzelne Zeile der Tabelle für die Abfrage berücksichtigt wird. Sollte für die Beantwortung einer Abfrage nur eine Teilmenge der Tabelle ausreichend sein, ist die Abfrage und/oder die Indexstruktur der Tabelle anzupassen.
Bei der Anzeige der Abfragen wird versucht, identische Muster zu konsolidieren. Das bedeutet, dass Abfragen, die sich nur über Filterelemente unterscheiden, unter Nutzung eines Platzhalters gruppiert werden (dies trifft im übrigen auf alle im MariaDB-Monitor dargestellten Abfragen zu). So wird:
where date < 01.01.2001
where date < 01.01.2002
jeweils zu
where data < ?
Die Query-Engine von MariaDB entscheidet bei einer Abfrage, ob das Nutzen eines Index sinnvoll ist. Sollte die Nutzung eines Index teurer bewertet werden als ein Table-Scan, verzichtet MariaDB auf die Nutzung des Index. Diese Einschätzung hängt u.a. von den gefilterten Elementen ab, sodass der Fall eintreten kann, dass dieselbe SQL-Abfrage (mit verschiedenen gefilterten Elementen) - bei wiederholter Ausführung - mit oder ohne Verwendung eines Index ausgeführt werden kann. Die Metrik „no_index_used_pct“ zeigt den Anteil der Ausführungen ohne Nutzung eines Index. In diesem Zusammenhang ist in Erwägung zu ziehen, ob die Filterung auf eine andere Variable ggf. eine konsistentere Indexnutzung zur Folge haben könnte.
Die Anzahl der Ausführung, die Dauer der Abfrage sowie der Anteil nicht genutzter Indizes helfen bei der Priorisierung. Für eine bessere Übersicht wird der Anteil der Abfragen mit einem Table-Scan grenzwertgesteuert eingefärbt (grau, orange, rot). Der Grenzwert lässt sich im Bereich „Configuration“ einstellen.
Statements with temp disc tables
Dieser Bereich gibt Aufschluss darüber, bei welchen Abfragen temporäre Tabellen angelegt wurden und ob dafür der Arbeitsspeicher verwendet werden konnte. In der Regel benötigt das Anlegen von temporären Tabellen im Arbeitsspeicher weniger Zeit als auf der Festplatte. Zudem sind auch die Operationen auf solchen Memory-Tabellen meist performanter. Daher sind temporäre "Disc-Tabellen" zu vermeiden. Die Metrik „tmp_tables_to_dsik_pct“ zeigt den Anteil temporärer Festplatten-Tabellen – hohe Werte sind ungünstig. Insbesondere in Verbindung mit einer langen Ausführungszeit.
Temporäre Tabellen sind z.B. bei Abfragen mit „group by“- oder „order by“-Anweisung notwendig. Sollte der Anteil der temporären Festplatten-Tabellen hoch sein, kann u.a. das Anpassen der Server-Variablen tmp_table_size und max_heap_table_size hilfreich sein.
Statements with warnings and errors
Die letzte Tabelle listet Abfragen mit Fehlern oder Warnungen. Die Anzahl der Ausführungen und der Anteil der Fehler und Warnungen helfen bei der Priorisierung. Zu beachten ist, dass eine Abfrage mehrere Fehler und Warnungen produzieren kann (z.B. Insert von mehreren hundert Zeilen: Ein falsches Daten-Format kann hier zu einer Fehlermeldung je Zeile führen). Ein Anteil größer als hundert Prozent ist daher möglich.
Index Statistics
Indizes können Abfragen beschleunigen. Jedoch ist auch Gegenteiliges möglich. Die Tabellen „Unused Indizes“ und „Index Cardinality“ sollen helfen, den Überblick zu behalten.
Unused Indexes
In dieser Tabelle werden alle Indizes getrennt nach Schema und Tabelle zusammengestellt, die seit dem letzten Serverstart nicht genutzt wurden. Indizes, die seit längerer Zeit nicht mehr verwendet wurden, sind gute Kandidaten für eine Löschung.
Indizes können eine Abfrage beträchtlich beschleunigen, z.B. indem nur noch auf die interessierenden Zeilen einer Tabelle zugegriffen werden muss. Schreibprozesse auf diese Tabelle werden hingegen langsamer, da neben den neuen Zeilen auch der Index aktualisiert werden muss. Es ist daher genau abzuwägen, ob ein Index notwendig und sinnvoll ist.
Index Cardinality
Die Kardinalität beschreibt, einfach gesprochen, das Verhältnis verschiedener Werte zur Gesamtzahl der Zeilen. So hätte das Attribut Geschlecht in einer Tabelle mit 1 Mio. Personen eine geringe Kardinalität, da lediglich zwei verschiedene Ausprägungen (Mann, Frau) existieren. Bei einer Filterung auf Geschlecht ist nicht davon auszugehen, dass die gefilterte Zeilenzahl klein ist (vermutlich 0,5 Mio.). Bei Indizes ist eine hohe Kardinalität in der Regel besser, da über einen Filter dann wenige Zeilen angesprochen werden. Im genannten Beispiel kann es z.B. je nach Abfrage möglich sein, dass sich die Query-Engine, trotz einer Filterung auf „Frau“ und einem Index auf Geschlecht, gegen die Nutzung des Index und für einen kompletten Table-Scan entscheidet.
Die Tabelle „Index Cardinality“ listet Indizes mit geringer Kardinalität. Bei den dargestellten Indizes ist in Erwägung zu ziehen, diese zu entfernen. Eine weitergehende Analyse zu ihrer Verwendung ist jedoch vorab empfehlenswert.
User Statistics
Die Nutzerstatistik liefert Anhaltspunkte, welchen Einfluss einzelne Nutzer auf die Gesamtperformance des Servers besitzen.
Events
Die Tabelle zu den Server-Ereignissen gibt eine Übersicht über definierte Ereignisse. Dazu gehört die Datenbank, auf der sie angelegt wurden sowie den verantwortlichen Nutzer. Der Status in Verbindung mit jeweils einem Datumsstempel zur Erstellung, Änderung und der nächsten Ausführung, helfen die korrekte Funktionsweise zu beurteilen.
InnoDB Status Output
Diese Seite zeigt den über die InnoDB-Speicher-Engine automatisiert zur Verfügung gestellten Report. Er enthält diverse Informationen, z.B. zu Transaktionen, I/O, Buffer, u.v.m.
Allocated Mem
Tiefergehende Informationen zur Speichernutzung von MariaDB lassen sich über die Seite „Allocated Mem“ einsehen. In der Regel verbessert sich die Performance des Datenbank-Servers mit größerem Arbeitsspeicher, da dann der Großteil der Daten „In Memory“ gehalten werden kann. In Abhängigkeit von der Größe des Arbeitsspeichers, lassen sich einige Variablen des MariaDB-Servers optimieren. Der größte Anteil des Arbeitsspeichers wird meist für den Buffer Pool eingeplant. Je größer dieser ist, desto höher ist die Wahrscheinlichkeit, dass eine Abfrage keine Festplattenoperation auslöst, d.h. die Abfrage lediglich mit dem Arbeitsspeicher beantwortet werden kann. Dies hat i.d.R. schnellere Antwortzeiten zur Folge.
Ein weiterer großer Anteil des Arbeitsspeichers wird bei BI-Anwendungen für die temporären Tabellen reserviert. Diese ermöglichen z.B. Sortierungs- oder Gruppierungsoperationen. Ein wesentlicher Unterschied zwischen Buffer Pool und dem Speicher für temporäre Tabellen ist, dass der Buffer Pool für alle Threads zusammen verwendet wird, der für temporäre Tabellen jedoch pro Thread separat. Das bedeutet, dass der Gesamtspeicher temporärer Tabellen mit der Anzahl gleichzeitiger Verbindung zunehmen kann. Im schlimmsten Fall bis zur „maximale Größer der temporären Tabellen“ mal der „maximalen Anzahl gleichzeitiger Verbindungen“. Neben den beiden „Speicherfressern“ innodb_buffer_pool_size und tmp_table_size (bzw. max_heap_table_size) gibt es weitere Variablen, die Thread-Spezifisch oder Thread-Übergreifend sind. Sie werden ebenfalls in dem Tab dargestellt. Sie beanspruchen in der Regel deutlich weniger Speicher als der Buffer-Pool und die temporären Tabellen.
Sollte mehr Speicher über die MariaDB-Variablen verplant werden, als der Server tatsächlich zur Verfügung stellt, kann es zu einem Absturz des Datenbank-Servers kommen.
Server Variables
In diesem Tab werden sämtliche Server-Variablen und Status-Variablen inkl. ihrer Werte dargestellt. Für eine selektive Anzeige kann die Suchmaske am oberen rechten Rand der Tabelle genutzt werden.
MaxScale
Auf dieser Seite befinden sich sämtliche Informationen, die das MaxScale Plugin „MaxInfo“ zur Verfügung stellt. Da sich dieses über einen MySQL-Client und SQL abfragen lässt, wurde es ebenfalls in die App integriert.
Wichtige Informationen sind u.a. die angebundenen Backend-Server mit ihrem zugehörigen Status, sowie verschiedenen Status-Variablen zu den vergangenen Ereignissen (z.B. Hangup-events und Error_events). Damit der MariaDB-Monitor die Daten des MaxInfo-Plugins abfragen kann, muss der hinterlegte Datenbank-Account ebenfalls für MaxInfo freigeschaltet worden sein. Dies lässt sich in MaxScale über die "maxscale.cnf" umsetzen. Ein Beispiel folgt weiter unten. Darüber hinaus muss das MaxInfo-Plugin über den Port 9003 erreichbar sein.
Configuration
Der Tab „Configuration“ bietet die Möglichkeit, die Darstellung und Funktionsweise der App anzupassen. Dazu gehören z.B. die Grenzwerte für das Einfärben von Werten, die Aktualisierungsfrequenz der Zeitpläne, die Anzahl der angezeigten Zeilen pro Tabelle oder die Größe des Arbeitsspeichers. Letzterer muss hinterlegt werden, da er sich derzeit noch nicht über den Datenbankserver abfragen lässt.
Notifications
Im oberen rechten Bereich der App befinden sich drei Notification-Icons. Ersteres stellt diverse Auffälligkeiten zusammen, die bei roter Einfärbung u.U. einen Eingriff erfordern. Dazu gehört die Anzahl der ungenutzten Indizes seit dem letzten Server-Start. Sie sind einer genauen Prüfung zu unterziehen und ggf. zu löschen. Ferner wird die Anzahl der Top-50 Abfragen mit einer Laufzeit größer als einer Sekunde angezeigt. Je nach Nutzung des Datenbankservers ist es ggf. sinnvoll, den Grenzwert anzupassen. Hintergrund der Kennzahl ist, dass oft ausgeführte Abfragen möglichst schnell beantwortet werden sollten.
In diesem Zusammenhang wird eine weitere Kennzahl ausgegeben. Sie zeigt die Anzahl der langsamsten Abfrage, die mehr als dreimal ausgeführt wurden. Auch hier kann es ggf. sinnvoll sein, die Grenzwerte anzupassen.
Die darunter befindlichen vier Kennzahlen fassen den zugewiesenen Arbeitsspeicher zusammen. Hintergrund ist die Prüfung, ob der zugewiesene Speicher den Arbeitsspeicher des Servers überschreitet.
Installation und Konfiguration
Die MariaDB-Monitor App wurde als R-Packet veröffentlicht und ist über Github verfügbar. Die Installation in R erfolgt über:
library(devtools)
devtools::install_github("INWT/MariaDB_Monitor")
Mit der Installation des Pakets wird im Verzeichnis des Users (~/.INWTdbMonitor/) die Konfigurationsdatei cnf.file angelegt. Für das Ausführen der App ist diese anzupassen, indem ein Datenbank-Account eingetragen wird. Dieser muss über ausreichend Rechte verfügen, um Performance-Daten abrufen zu können (z.B. auf das performance_schema). Folgendes Create-Script stellt eine Möglichkeit dar, sollte jedoch unter dem Aspekt der Sicherheit angepasst werden:
CREATE USER 'MariaDBstat'@'%' IDENTIFIED BY 'abc';
GRANT SELECT, PROCESS ON *.* TO 'MariaDBstat'@'%';
GRANT SELECT ON `information\_schema`.* TO 'MariaDBstat'@'%';
GRANT SELECT ON `mysql`.* TO 'MariaDBstat'@'%';
GRANT SELECT ON `performance\_schema`.* TO 'MariaDBstat'@'%';
GRANT SELECT, EXECUTE, SHOW VIEW ON `sys`.* TO 'MariaDBstat'@'%';
FLUSH PRIVILEGES;
Der Username und das Passwort sind in Verbindung mit dem Datenbank-Host und -Port in die Konfigurationsdatei cnf.file zu übernehmen. Die Angabe einer Datenbank ist optional. Die Eingabe der Account-Daten kann direkt in der Datei cnf.file vorgenommen werden oder über den Aufruf der Wizard-Funktion:
promptCnfData()
Die Konfigurationsdatei besitzt folgenden Aufbau:
[client]
user=
password=
database=
host=
port=
Außerdem ist sicherzustellen, dass folgender Eintrag in der my.cnf des MariaDB-Servers unter mysqld gesetzt ist. Dieser garantiert, dass der Server Performance-Daten erhebt.
performance_schema = on
Die App lässt sich mit korrekter Konfiguration auf dem Desktop-PC mit RStudio oder auf einem Shiny Server starten. In RStudio reicht folgender Code zum Starten des MariaDB-Monitors:
library("INWTdbMonitor")
startApplication()
Konfiguration für MaxScale
Der MariaDB-Monitor erkennt automatisch, ob der konfigurierte Datenbank-Server mit MaxScale verbunden ist. Um Daten des MaxInfo-Plugins anzeigen zu können, ist es notwendig, dass der konfigurierte Datenbank-Account auch für MaxInfo angelegt wurde.
Folgende beispielhafte Konfiguration in der maxscale.cnf ist eine Möglichkeit:
[MaxInfo]
type=service
router=maxinfo
user=MariaDBstat
passwd=abc
[MaxInfo Listener]
type=listener
service= MaxInfo
protocol=MySQLClient
address=xxx.xxx.xxx.xx
port=9003