Der flexible Allrounder in Data Science - Python
Die offene Programmiersprache Python entstand ab dem Jahr 1989 als Nachfolger der Programmiersprache ABC und wird von der Python Software Foundation aktiv weiterentwickelt. Die Sprache ist eine sogenannte Multi-Paradigmen-Sprache und unterstützt verschiedene Programmierkonzepte, etwa objektorientierte, strukturierte und wesentliche Teile funktionaler Programmierung. Dabei folgt sie der Philosophie, Lesbarkeit, Explizitheit und Einfachheit durch ihre Kernprinzipien zu unterstützen. Mit der dritten Version Python 3 ist Python nicht mehr abwärtskompatibel. Das bedeutet, dass wesentliche Teile früherer Versionen nicht mehr unterstützt werden. Da dennoch viele Programme in früheren Versionen geschrieben wurden, wird Python 2 weiterhin unterstützt. Python ist keine reine Statistikumgebung, doch durch die hohe Relevanz bei der Umsetzung von Data Science- und Statistikprojekten darf die Programmiersprache in unserem Vergleich der Statistik-Softwares nicht fehlen.
Ein wesentlicher Vorteil von Python ist die Community, welche regelmäßig neue Open Source-Pakete für die Sprache veröffentlicht. Diese werden mittels PyPi, dem Python Package Index veröffentlicht. Aktuell enthält dieser weit über 130.000 Pakete, ein Zeichen für die ungeheure Flexibilität der Sprache. Ob Spiel- oder Webentwicklung, Python kann für die unterschiedlichsten Anwendungsbereiche eingesetzt werden. Somit ist klar, dass die Sprache in erster Linie eben eine Programmiersprache und keine klassische Statistik-Software ist. Der Einsatz in Datenprojekten wird daher erst durch eine Vielzahl von performanten Paketen ermöglicht, welche sehr einfach nachinstalliert werden können. Diese Pakete werden zum Teil durch die Community, zum Teil durch Universitäten oder Technologie-Unternehmen bereitgestellt und weiterentwickelt. Durch die hohe Flexibilität, die relativ einfache und elegante Syntax und die Vielzahl an Paketen erfreut sich Python extrem hoher und wachsender Beliebtheit.
Im folgenden wird Python hinsichtlich des im ersten Teil der Artikelserie vorgestellten Kriterienkatalogs genauer untersucht:
Methoden: Statistik vs. Machine Learning
Python ist nicht als Statistik-Software entstanden. Daher ist dies auch nicht die Kernkompetenz dieser Sprache. Durch unterschiedliche, umfangreiche Pakete beherrscht es jedoch mittlerweile eine beachtliche Menge an Modellen und statistischen Verfahren, insbesondere Features aus dem Machine Learning-Bereich. Numerische Berechnungen werden durch numpy, Methoden des Machine Learnings durch scikit-learn, statistische Verfahren durch statmodels bereitgestellt. Im wissenschaftlichen Machine Learning-Bereich hat sich Python mittlerweile als State of the Art etabliert. Das bedeutet, dass Verfahren aus diesem Bereich in hoher Zahl für Python verfügbar sind. Insbesondere im Deep Learning-Bereich kann keine der hier vorgestellten Alternativen mit Python mithalten. Für klassische Statistik, etwa Hypothesentests, gilt das nicht. Hier beherrscht Python die gängigsten Grundlagen, aber sämtliche Alternativen bieten hier mehr, insbesondere R. Für Predictive Analytics und Machine Learning ist Python aber eine exzellente Alternative, die bei der Anschaffung einer Data Science-Umgebung berücksichtigt werden sollte.
Bedienkonzept
Python ist auf MacOS und Linux bereits vorinstalliert, unter Windows ist das leicht nachzuholen. Nach der Installation bietet Python aber lediglich eine Kommandozeile an. Damit lassen sich jedoch Python-Skripte, die in einem beliebigen Texteditor geschrieben werden, bereits ausführen. Pakete und Entwicklungsumgebungen, die Python zu einer "Statistik-Software" machen, müssen erst nachinstalliert werden. Distributionen wie conda können dabei helfen, dennoch ist die Installation sowie die Bedienung für viele Anwender erst einmal mühsam und erfordert etwas Einarbeitungszeit. Ist diese gemeistert, spielt Python seine Vorteile als vollständige, leistungsfähige Programmiersprache mit vielen entwicklerfreundlichen Ideen jedoch aus. Im Vergleich zu anderen Sprachen ist Python relativ gut lesbar, erinnert an manchen Stellen gar an Pseudocode. Dies wird beispielsweise durch den Zwang auf eine gewisse Codeformatierung bei gleichzeitigem Verzicht auf allzu viele Klammern garantiert. Durch die Unterstützung unterschiedlicher Programmierparadigmen wird dem Entwickler gleichzeitig eine große Freiheit bei der Umsetzung seiner Ideen überlassen. So ist der Anwender weder gezwungen objektorientiert zu arbeiten wie in Java, noch funktional wie in R. Beides ist in Python jedoch bei Bedarf möglich.
Nutzungsintensität und -frequenz
Die grundsätzliche Einarbeitung in Python kann schnell gehen - zum Beispiel in einem Crashkurs in etwa drei Tagen. Dann lassen sich auch schon erste Datenanalysen fahren. Durch die große Community ist online schnell Hilfe verfügbar, etwa auf StackOverflow. Die Beherrschung weitergehender Konzepte der Sprache kann jedoch dauern, auch den langjährigen Anwender kann Python noch überraschen. Zudem sollte die Sprache oft genutzt werden und eignet sich somit eher für Personen, die regelmäßig Datenanalysen durchführen. Hier unterscheidet sich Python nicht von anderen Programmiersprachen, wie etwa R.
Automatisierbarkeit
Python-Skripte lassen sich auf jedem Computer, auf welchem Python und die im Skript genutzten Pakete installiert sind, ausführen und somit (etwa über cron-jobs oder Jenkins) automatisieren. Weiterhin bietet Python etwa mit flask die Möglichkeit, sehr einfach Webserver aufzusetzen, die sich wiederum von anderen Programmen ansteuern lassen und dann beliebige Output-Formate, etwa .json-Dateien oder .csv-Dateien, zurückgeben. Bei der Frage der Automatisierung spielt Python in der ersten Liga und wird deshalb auch in vielen professionellen Bereichen eingesetzt.
Umfang der zu analysierenden Daten
Grundsätzlich ist Python so konzipiert, dass zu analysierende Daten komplett in den Arbeitsspeicher geladen werden müssen. Es ist möglich, Cloud-Services wie AWS zu nutzen, welche Images anbieten, auf welchen Python und sämtliche für Datenanalysen nötige Pakete bereits vorinstalliert sind. Mittels pyspark kann Python jedoch auch bspw. mit Spark auf einem inhouse Cluster zusammenspielen.
Sicherung der Datenqualität
Python bietet über Pakete wie pandas, statmodels und scikit-learn jede Menge an (automatisierten) Methoden, um mit fehlenden Werden, Ausreißern, fehlerhaften Zeitdaten etc. umzugehen. Hier sind dem Anwender keine Grenzen gesetzt. R bietet auf diesem Feld jedoch neue Methoden an, die zum Teil in Python nicht umgesetzt sind, beispielsweise im Bereich Ausreißertests. Zudem kann, falls mit Textdaten gearbeitet wird, Encoding ein leidiges Thema sein, insbesondere bei Python 2, welches Textdaten nicht automatisch als Unicode einliest.
Installationsszenario
Python ist auf allen gängigen Unix-Derivaten vorinstalliert. Auf Windows kann die Installation einiger Pakete Probleme bereiten, hier ist die Nutzung der Distribution conda zu empfehlen. Für die Nutzung neuester Entwicklerversionen von Paketen hat man die Möglichkeit, den Code auszukompilieren. Etwa über jupyter notebooks lässt sich zudem auf Servern sehr einfach über den Browser programmieren.
Performance
Bei der Anschaffung einer Data Science-Umgebung kann Performance eine entscheidende Größe sein. Eine generelle Aussage lässt sich hier nicht treffen, da unterschiedliche Pakete einen unterschiedlichen Fokus auf Performance legen. Die grundsätzlichen Rechenoperationen sind in Python meist schneller als die Alternativen in dieser Zusammenstellung, auch als R. Auch das Standard-Paket für Datenoperation in Python, pandas, ist etwa auf einem Level mit dem schnellsten entsprechenden Paket in R, data.table. In scikit-learn lassen sich die meisten Operationen mittels des Parameters n_jobs zudem sehr einfach parallelisieren. Für die Parallelisierung des eigenen Codes lassen sich Pakete wie multiprocessing nutzen. Zudem lässt sich mittels Cython Code nach C auslagern und somit zeitkritische Prozesse relativ einfach beschleunigen. Weitere Verbesserungen lassen sich durch die Nutzung alternativer System-Bibliotheken zur Beschleunigung von Methoden der linearen Algebra nutzen, etwa OpenBLAS oder ATLAS.
Rechteverwaltung
Python lässt sich mit eingeschränkten Rechten ausführen. Die Python-Installation greift auf Module im PYTHONPATH zu, welche bspw. zentralisiert gemanagt werden können, etwa auf einem Netzlaufwerk. Der Zugriff über Daten lässt sich beispielsweise über das Rechtemanagement in der SQL-Datenbank regeln. Python bietet Unterstützung für alle gängigen Datenbanksysteme an.
Lizenzmodell
Python ist Open Source und steht unter einer GPL-kompatiblen Lizenz. Es kann kostenlos für private und kommerzielle Projekte eingesetzt werden. Pakete oder Dateien stehen unter anderen Lizenzen, sind jedoch, sofern sie unter PyPI auffindbar sind, frei nutzbar. Eigene Pakete können darüber ebenfalls relativ einfach verbreitet werden.
Integration mit anderen Anwendungen
Python bietet unzählige Pakete zur Nutzung unterschiedlichster Datenformate, APIs, Datenbankmodelle und anderer Programmiersprachen. Sämtliche gängigen Datenbanken wie MySQL, PostgreSQL, Oracle, teradata, Amazon redshift, Apache Spark usw. lassen sich sehr einfach anbinden. Auch die Integration in Anwendungen wie SPSS, SAS, KNIME, RapidMiner, dataiku ist gegeben. Mit Jython oder Cython sind auch Integrationen in andere Sprachen möglich. Falls keine Integration möglich ist, lassen sich Daten etwa über einen in Python gestarteten Server austauschen. Python ist hier auf der Höhe der Zeit.
Branchenspezifische Anforderungen
Python lässt sich durch seine Flexibilität in beliebigen Branchen einsetzen und ist auch in unterschiedlichsten Bereichen verbreitet. Gerade in klinischen Studien oder der Pharmaindustrie ist Python durch die fehlende Unterstützung ausgefallenerer Hypothesentests jedoch unterrepräsentiert.
Akzeptanz
Python ist extrem weit verbreitet, die Machine Learning-Pakete werden mittlerweile auch im Data Science-Bereich sehr stark genutzt. Somit ist die Akzeptanz der Sprache und damit einhergehender Features entsprechend hoch.
Support
Durch die große Community gibt es zahlreiche frei verfügbare Tutorials, Handbücher und Guides. Die offizielle Dokumentation von Python und der gängigen Data Science-Pakete ist zudem äußerst umfangreich. Weiteren Support erhält man in diversen Foren wie StackOverflow, welche durch die große Community gestützt werden.
Angebot an Schulungen
Online sind jede Menge Kurse in Python mit einem Fokus auf Data Science-Anwendungen verfügbar, etwa bei Udacity, Coursera, aber auch frei etwa bei Kaggle. Zahllose kommerzielle Anbieter runden das Angebot ab, sind aber nicht immer auf statistische Anwendungen fokussiert. An den Universitäten wird Python meist an Informatik-Fachbereichen gelehrt.
Vorhandene Qualifikation der Mitarbeiter
Python ist vor allem Software-Entwicklern bzw. Informatikern ein Begriff. Im statistischen Bereich ist die Sprache relativ neu und wird noch nicht umfänglich an den Universitäten gelehrt. Durch den großen Erfolg und die vergleichsweise einfache Syntax verbreiten sich Python-Kenntnisse aber relativ schnell, jedenfalls unter programmieraffinen Anwendern. Für alle anderen kann die Skriptsprache gerade im Vergleich zu Klickoberflächen eine größere Hürde darstellen.
Stabilität/Innovativität
Die Programmiersprache Python wird seit mehr als 25 Jahren im professionellen Bereich eingesetzt und stetig weiterentwickelt. Gleichzeitig hängt die Stabilität natürlich auch von der Qualität der eingesetzten Pakete ab, welche durchaus unterschiedlich sein kann. Gerade die gängigen Data Science-Pakete weisen jedoch durchweg eine hohe Stabilität auf und sind auch stärker konsolidiert als beispielsweise bei R. Neue Verfahren werden ständig mit eingebunden. Dies gilt besonders für Verfahren aus den Bereichen Deep Learning / Machine Learning. Bei statistischen Verfahren hinkt Python des öfteren hinterher, diese werden häufig direkt in R veröffentlicht.
Python ist in den Bereichen Big Data, Statistik, Predicte Analytics, Machine Learning und Data Science extrem stark am Wachsen und gehört zu den am stärksten genutzten Skriptsprachen in diesen Feldern. Das liegt vor allem an der extrem hohen Flexibilität und Vielseitigkeit, die die Sprache und das Universum an Paketen mit sich bringt. Zudem ist sie relativ leicht erlernbar, zukunftssicher und wird durch eine starke Community getragen. Lediglich bei stärkerem Fokus auf klassische statistische Verfahren sollte man sich bei der Anschaffung gut überlegen, ob nicht ein anderes Programm besser geeignet ist.
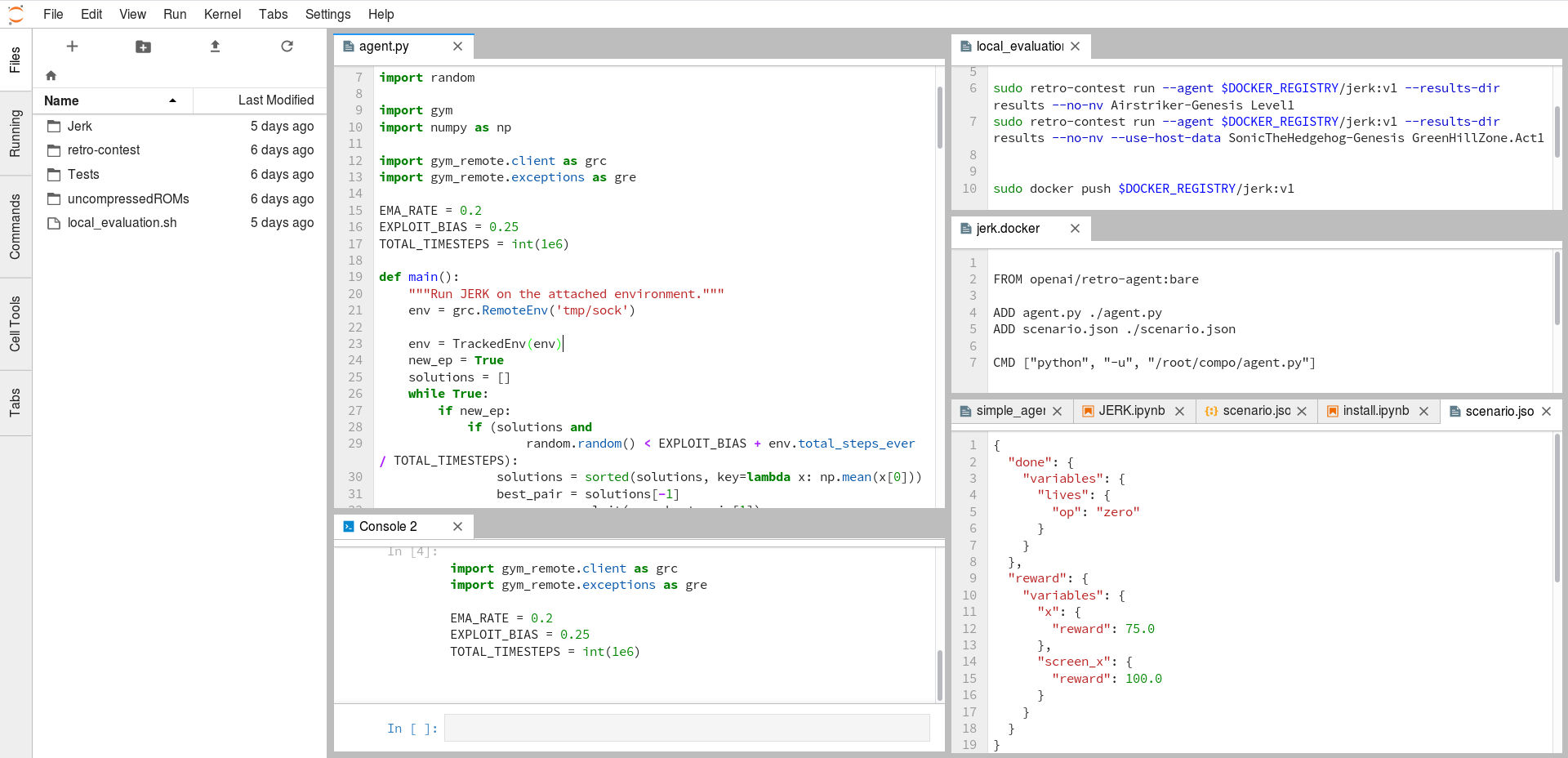 Python innerhalb von Jupyter Lab. Hier lassen sich Python Skripte mit zugehöriger Konsole ebenso öffnen wie andere Dateien.
Python innerhalb von Jupyter Lab. Hier lassen sich Python Skripte mit zugehöriger Konsole ebenso öffnen wie andere Dateien.
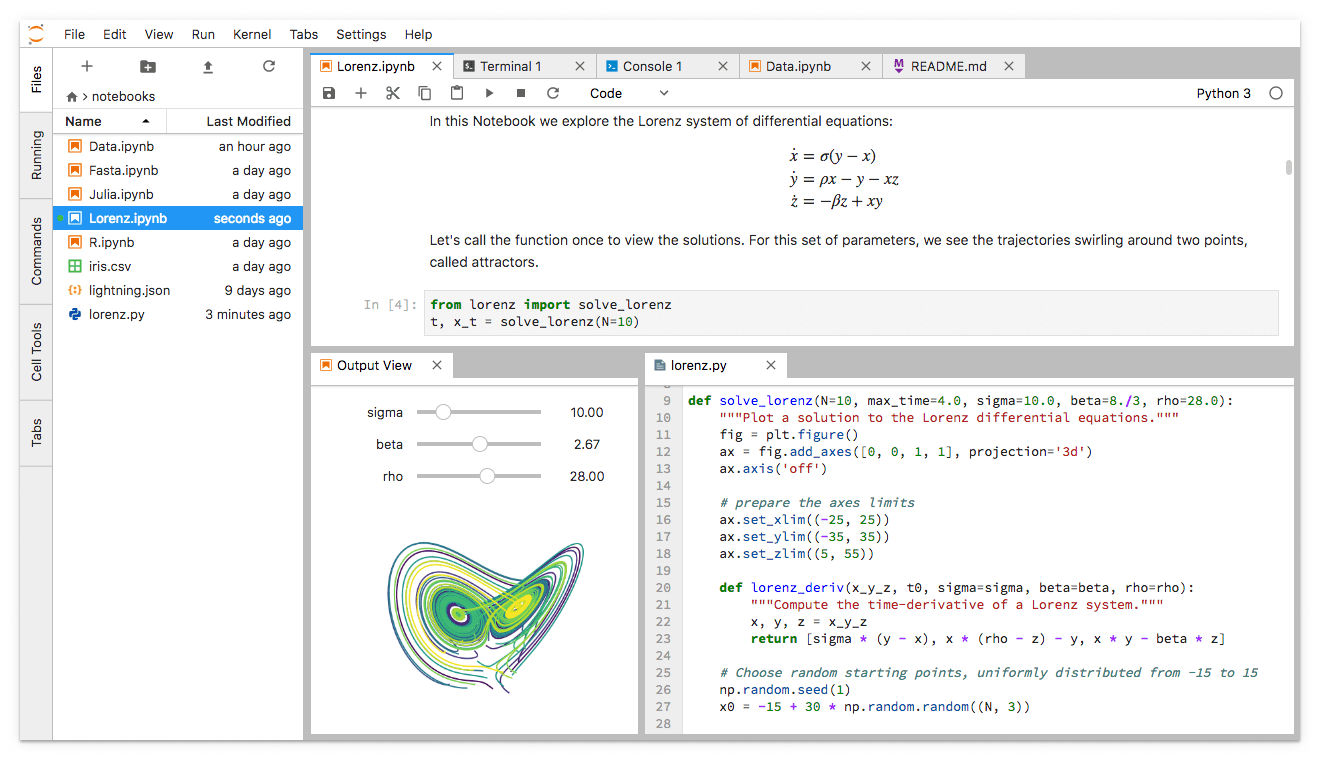 Jupyter Lab bietet auch im Browser eine benutzerfreundliche Oberfläche für das Arbeiten mit Python.
Jupyter Lab bietet auch im Browser eine benutzerfreundliche Oberfläche für das Arbeiten mit Python.
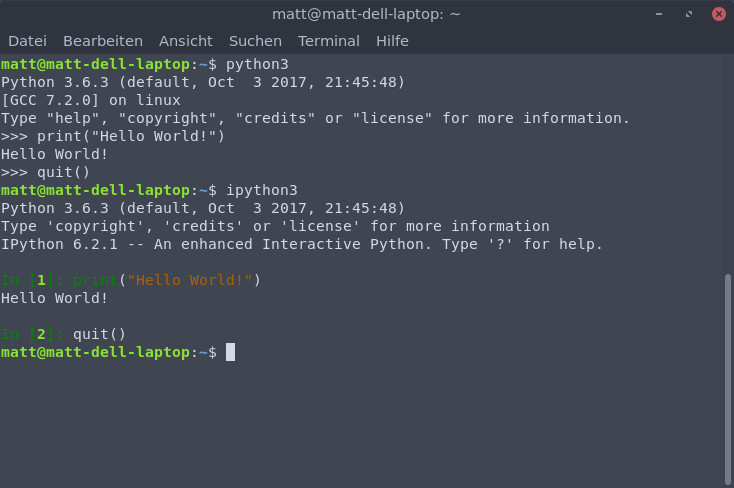 Beispiel einer Python-Konsole
Beispiel einer Python-Konsole





