TabPFN: Die KI-Revolution für tabulare Daten
Die schnelle Entwicklung von KI-Modellen, die auf großen Datenmengen vortrainiert werden, hat es stark vereinfacht, unstrukturierte Daten wie Text und Bilder auszuwerten. Dennoch werden in vielen Kernanwendungen im Feld Predictive Analytics (PA) weiterhin tabulare Daten betrachtet. Daher stellt sich die Frage, welchen Mehrwert die neuen KI-Methoden für die Analyse tabularer Daten bringen. Wird KI auch diesen Bereich verändern? Die Fähigkeiten der neuen Methode TabPFN sprechen dafür, dass dem so sein wird. Es handelt sich um ein Foundation-Modell, welches im Januar 2025 im renommierten Nature-Journal veröffentlicht wurde. Auf unserem bereits mehrmals als Benchmark verwendeten Datensatz übertrifft es den Algorithmus XGBoost für kleine Beobachtungszahlen deutlich in der Prognosegenauigkeit. TabPFN punktet zudem mit einer einfach umzusetzenden Unsicherheitsquantifizierung. Mit einer größeren Zahl von Trainingsbeobachtungen (6000) generiert TabPFN eine ähnliche Prognosegenauigkeit wie XGBoost.
Die grundlegende Veränderung in der Entwicklung dieses Modells im Vergleich zu Algorithmen wie XGBoost liegt darin, dass die Idee des Vortrainings auf den Fall von Prognosen für tabulare Daten übertragen wird. TabPFN wurde auf einer großen Zahl von künstlich generierten Datensätzen vortrainiert, sodass das Modell out-of-the-box über ein inhärentes Wissen zu tabularen Daten verfügt. Mehr dazu schreiben wir im Abschnitt Funktionsweise und Potenzial von TabPFN unten.
Datensatz
Über unseren Partner LOT Internet haben wir Zugang zu einem Datensatz mit 8000 Datenpunkten über Fahrzeuge erhalten, die auf der Plattform mobile.de angeboten werden. Wir prognostizieren den Fahrzeugpreis, während wir verschiedene Fahrzeugmerkmale wie Kilometerstand, Alter und Motorenstärke als Einflussgrößen betrachten. Die Anwendung von Foundation-Modelle für Predictive Analytics beschäftigt uns bereits seit einer Weile. In diesem Blogartikel dokumentieren wir, wie sich Large-Language-Models (LLMs) nutzen lassen, um tabulare Prognosen zu erstellen. Dort verwenden wir auch Freitexte aus den Fahrzeuganzeigen, in denen Details zu den Fahrzeugen von den Verkäufer*innen beschrieben werden. Der dort genutzte Datensatz enthält außerdem weitere tabulare Features zur Fahrzeugausstattung.
Ergebnisse auf Autopreisdaten
Wir verwenden in diesem Fall nicht die Freitextdaten, weil TabPFN diese nicht ohne größeren Aufwand verarbeiten kann. Kategoriale Features wie zum Beispiel der Kraftstofftyp (Diesel, Benzin etc.) können aber ohne Probleme einbezogen werden. Auch fehlende Werte berücksichtigt das Modell ohne wesentlichen Mehraufwand oder Verlust von Beobachtungen. Zur Nutzung von TabPFN gibt es ein Python-Paket, eine Anleitung findet sich im TabPFN-Github-Repository. Die Ergebnisse in Tabelle 1 zeigen, dass TabPFN für 600 Beobachtungen eine bessere Performance bringt als XGBoost. Die Prognosegüte für 6000 Beobachtungen ist dagegen ähnlich gut. Mit TabPFN lassen sich sehr schnell und einfach gute bis sehr gute Prognosen erstellen. Aber auch die Prognosen mit XGBoost wurden mit wenig Zeitaufwand erstellt. Wir haben ca. 10 Minuten für ein manuelles Hyperparametertuning verwendet. Zu berücksichtigen ist auch, dass wir kein Feature-Engineering durchgeführt haben. Es wäre spannend zu sehen, wie dieser Aspekt den Vergleich beeinflusst.
| Model | Trainingsbeobachtungen | MAPE (%) | Median APE (%) |
|---|---|---|---|
| TabPFN | 600 | 14.2 | 7.3 |
| XGBoost | 600 | 17.3 | 8.5 |
| TabPFN | 6000 | 13.1 | 6.9 |
| XGBoost | 6000 | 13.3 | 7.0 |
Tabelle 1: Ergebnisse mit TabPFN im Vergleich zu XGBoost auf dem Testdatensatz von 2000 Beobachtungen. Anzahl Trainingsbeobachtungen = 6000. MAPE = Mean absolute percentage error. Median APE = Median absolute percentage error. Features: 9, kategoriale Features: 6.
Prognosegeschwindigkeit
Die Autor*innen von TabPFN beschreiben es als eine potenzielle Schwäche der Methode, dass die Erstellung von Prognosen langsam sein kann im Vergleich zu Methoden wie XGBoost - inbesondere wenn es sich um eine Anzahl von Beobachtungen handelt, die in der Nähe von 10.000 liegt. Für höhere Beobachtungszahlen ist die Methode nicht geeignet. Wenn wir eine CPU nutzen, bestätigt sich der Geschwindigkeitsnachteil. Unser Trainingsdatensatz hat 6000 Beobachtungen bei 9 Features, während der Testendatensatz 2000 hat. Auf einem leistungsfähigen Laptop brauchte die Prognose auf der CPU 23 Minuten.
Dagegen stellte sich die Prognose auf einer GPU (getestet auf einer Nvidia L40S) als sehr schnell heraus - 1,15 Sekunden für alle 2000 Beobachtungen. Wenn man über eine GPU verfügt, ist der Geschwindigkeitsnachteil also nicht mehr so schwerwiegend. Zum Beispiel geben die TabPFN-Autor*innen als Referenz an, dass eine Prognose für eine Beobachtung mit dem CatBoost Algorithmus 0,0002 Sekunden braucht. Für 2000 Beobachtungen wären das also 0,4 Sekunden. Damit verglichen ist TabPFN ca. 3 mal langsamer.
Vorteil Unsicherheitsquantifikation
Die Entwickler von TabPFN schreiben im Nature-Paper, dass das Modell die Bayesianische posterior predictive distribution approximiert. Eine weitere Referenz ist dieses Paper. Dadurch gibt das Modell für jede Beobachtung im Testdatensatz eine Verteilung aus, die die Unsicherheit der Prognose quantifiziert. Im Code lassen sich Quantile dieser Verteilung wählen, die ausgegeben werden sollen. Auf diese Art ist es z.B. möglich 95%-Unsicherheitsintervalle zu erstellen. In Abbildung 1 sind diese Intervalle für unseren Testdatensatz abgebildet. Diese direkte Möglichkeit der Unsicherheitsquantifizierung ist ein großer Vorteil gegenüber der Nutzung von XGBoost und auch der Nutzung von LLMs zur Prognose einer metrischen Zielvariable. Mit XGBoost oder LLMs ist es nicht ohne weiteren Aufwand möglich, Prognoseintervalle zu erstellen.
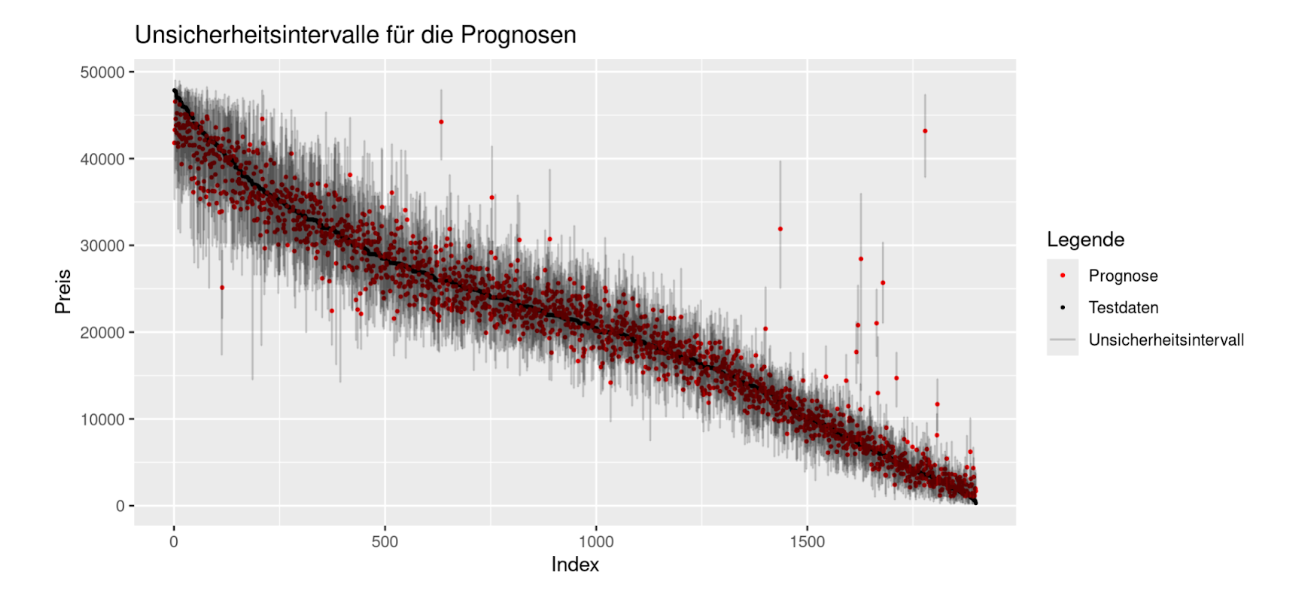
Abbildung 1: Unsicherheitsintervalle für die Prognosen auf den Testdaten. Die Werte sind von links nach rechts absteigend geordnet, orientiert an den wahren Preisen in den Testdaten.
Es stellt sich heraus, dass in unserem Fall 94,4 % der wahren Testdatenpunkte innerhalb der Unsicherheitsintervalle der Prognose liegen. Dieser Wert liegt sehr nahe am vorab spezifizierten Wert von 95 %, was für die Qualität der Unsicherheitsquantifizierung spricht.
Funktionsweise und Potenzial von TabPFN
TabPFN funktioniert grundlegend anders als bisherige state-of-the-art Algorithmen ohne Vortraining. Für das Vortraining wurde eine große Zahl an künstlichen Datensätzen generiert. Dabei wurde eine möglichst vielfältige Sammlung an Daten erstellt. Dadurch lernt das Modell anhand von Beispielen, welche funktionalen Zusammenhänge zwischen Features und Zielvariable bei tabularen Daten vorkommen können.
Der Ansatz unterscheidet sich von einem traditionellen Vorgehen, bei dem ein*e Analyst*in manuell eine Modellklasse auswählt, die zu den vorliegenden Daten passt. Zum Potenzial der Methode treffen die Autor*innen von TabPFN folgende Einschätzung:
- Die beste Performance wird für Datensätze mit bis zu 10K Beobachtungen und bis zu 500 Features erwartet
- Für größere Datensätze und komplexe Zusammenhänge performen Ansätze wie CatBoost und XGBoost tendenziell besser
- Feature Engineering, Data Cleaning und Fachwissen zum Anwendungsbereich der Methode sind weiterhin notwendig, um die besten Prognoseergebnisse zu erzielen
Zudem erstellt das Modell Prognosen auf Grundlage ganzer Datensätze. Als Input nimmt es den gesamten Trainingsdatensatz und die Testdatensatz-Features. Der Output ist der Vektor aus Prognosen auf dem Testdatensatz. Die Autoren von TabPFN nennen diesen Ansatz In-Context Learning, welcher sich von XGBoost oder auch einfachen Modellen wie der linearen Regression darin unterscheidet, dass letztere Modelle für jede Test-Beobachtung einzeln eine Prognose erstellen, nachdem das Modell trainiert wurde.
In Analogie zum few-shot-learning bei LLMs kann man es sich so vorstellen, dass der Trainingsdatensatz eine Sammlung von Input-Output Beispielen umfasst, die dem Modell im Prompt übergeben werden. Das Modell erstellt als Antwort Prognosen für die Testdaten.
Um zu verdeutlichen, was diese Besonderheit in Bezug auf die Reproduzierbarkeit der Ergebisse bedeutet, haben wir untersucht, was passiert, wenn wir für ein Viertel der Beobachtungen aus unserem Testdatensatz Prognosen erstellen möchten und dieses mal aber die restlichen Testbeobachtungen nicht an TabPFN weitergeben. Bei Algorithmen wie XGBoost würde dies keinen Unterschied machen, weil diese für jede Beobachtung einzeln eine Prognose erstellen. Für TabPFN stellte sich dagegen heraus, dass sich die Prognosen verändern. Im Mittel weichen die Preisprognosen um 1,50 € voneinander ab, im Maximum sogar um 9,10 €. Hierbei handelt es sich noch um eine Schwäche von TabPFN. Es wäre zum Beispiel schwer zu rechtfertigen, wenn die Kreditwürdigkeit von Kund*innen unterschiedlich prognostiziert wird, je nachdem welche anderen Kund*innen zeitgleich ein Rating erhalten.
Ein anderer Nachteil von TabPFN ist es, dass kein klassisches Modellobjekt gespeichert werden kann, welches die erlernten Informationen aus den Trainingsdaten in eine kleine Beschreibung komprimiert. Zum Beispiel kann ein lineares Modell über die geschätzten Koeffizienten beschrieben werden, was nur sehr wenig Speicherplatz erfordert. Ein weiteres Beispiel: Das XGBoost-Modellobjekt für unseren Benchmark war 3,8 MB groß. Dagegen erforderte das gespeichterte TabPFN-Modellobjekt in unserem Fall 1,1 GB.
Zudem erspart das Speichern des Modellobjektes bei der Nutzung von XGBoost viel Zeit, wenn weitere Prognosen erstellt werden sollen, weil nicht neu trainiert werden muss. Aufgrund der ungewöhnlichen Funktionsweise von TabPFN hat es diesen Vorteil nicht und ist aktuell noch vergleichsweise langsam in der Prognosererstellung.
Zusammenfassung
TabPFN ist eine sehr neue Methode, um Prognosen auf tabularen Daten zu erstellen. Die Funktionsweise ist fundamental anders als konkurrierende Methoden. TabPFN hat sehr viel Aufmerksamkeit erfahren und hat das Potenzial, Predictive Analytics gehörig umzukrempeln. Wir haben TabPFN zunächst an einem Beispiel ausprobiert und die Performance mit XGBoost verglichen.
In unserem Beispiel bestätigen sich die Ergebnisse aus dem Nature Paper zu TabPFN. Die Methode ermöglicht unter bestimmten Umständen eine deutlich bessere Prognosegenauigkeit als z.B. XGBoost. Dies gilt speziell, wenn der Stichprobenumfang eher gering ist (in unserem Fall bei 600 Beobachtungen). Bei 6000 Beobachtungen liegen TabPFN und XGBoost dicht beieinander.
Dabei erforderte TabPFN keinerlei Hyperparameteroptimierung, wie wir es standardmäßig bei XGBoost durchführen. Ein weiterer Vorteil ist die einfache Möglichkeit, Prognoseintervalle für die einzelnen Beobachtungen zu erstellen.
Bei der Prognosegeschwindkeit ist TabPFN XGBoost um ca. einen Faktor 3 unterlegen, vorausgesetzt, dass eine GPU verfügbar ist. Mit CPU ist der Geschwindigkeitsnachteil gravierender. Eine anderer Nachteil ist es, dass eine Prognose für die gleiche Beobachtung sich geringfügig ändern kann, je nachdem welche anderen Prognosen gleichzeitig gemacht werden.
Nach diesem ersten Test werden wir uns TabPFN auf jeden Fall genauer ansehen und weitere Benchmarks erstellen.